XBRLファイルから会社情報を取得するクラスを書いた
はじめに
EDINET APIを用いて企業情報を取得するPythonコードを書いた。
EDINETからダウンロードしたXBRLから有価証券報告書の情報を抜き出す
だいぶ日が開いてしまいましたが、これまで書いた記事で進めていた有価証券報告書の情報取得を進めていきます。
Arelleを使ったXBRLの解析
Googleで調べると先人たちの記事が出てくるのでこれらを参考に作成していきます。
ゼロから始めないXBRL解析(Arelleの活用) #Python
Pythonで財務分析】XBRL解析のためにArelleをインストール
EDINET開示のXBRLデータから、平均給与等の従業員情報を自動で抽出してみよう
自前でXBRLパーサーを書いてもいいけど、海外株まで手を出すとほぼ間違いなく泥沼にハマるから パッケージングソフトか、OSSを使いましょう。 OSSで認証とれているのはArelleのみで、個人利用だとArelle一強という状態のようです。
XBRLの解析がやりたいことではないのでOSS使っていきましょう。
Arelleの環境構築
https://github.com/Arelle/Arelle
githubを除いてみると、pipにRelease版のアップロードされているようです。 フルセットでDLするためこのように叩いてあげれば準備OKです。
pip install arelle-release[Crypto,DB,EFM,ObjectMaker,WebServer]
Python v.3.10系を使っていたのですがパッケージ内の一部でLogger系のError吐いてたのでPython v3.12を使えばとりあえず動作しました。
下準備
EDINET APIを用いてDLすると、XBRLを含むファイルはZIPで取得できます。
金融庁は2000年代で時代が止まっているのか、2chでよく見た「Zipでくれ」ってやつを踏襲しているのですが、今は令和なので余計なお世話です。
面倒なのですが、Zipを解凍して、XBRLファイルを取り出す処理が必要になってきます。
なのでこのように書きました。 最終的には関数にしたら良いですが、ZIPファイルは直打ちで書いています。
ArelleはPathLibに対応していないのでGlobで取ってきたパスを突っ込んでます。 フォルダの中に複数XBRLファイルが含まれているケースの場合、2つ目以降欠損しますがそんなフォルダはまだ見かけていないのでこの実装でよいですね。
# ZIPファイルのパス
zip_file_path = 'S100FFK6_有価証券報告書_株式会社 クボタ.zip'
# 一時フォルダを作成
temp_dir = 'temp'
os.makedirs(temp_dir, exist_ok=True)
# ZIPファイルを一時フォルダに展開
with zipfile.ZipFile(zip_file_path, 'r') as zip_file:
zip_file.extractall(temp_dir)
print(temp_dir)
xbrl_file = glob.glob(temp_dir+'/**/PublicDoc/*.xbrl')[0]
企業情報の取得
金融庁のサイトから上場/非上場の企業情報一覧を取得します。
上記サイトの最下段に、EDINETコードリストというCSVファイルがあるのでDLしておきます。

ここに含まれるリストは、有価証券報告書を提出している企業の一覧です。 上場企業だけでなく、非上場であっても大きな会社というのは沢山あります。 そうした会社も、有価証券報告書を提出してるようです。
XBRLファイルの中にある情報を突合して、企業名や業種、上場、非上場の情報を判断するのに使います。
def makeEdinetCompInfoList(edinetcodedlinfo_filepath):
edinet_info = pd.read_csv(edinetcodedlinfo_filepath, skiprows=1,
encoding='cp932')
edinet_info = edinet_info[["EDINETコード", "提出者業種"]]
edinet_info_list = edinet_info.values.tolist()
return edinet_info_list
def main():
#~~~~中略~~~~~
edinetcodedlinfo_filepath = '.\\EdinetcodeDlInfo.csv'
edinet_info_list = makeEdinetCompInfoList(edinetcodedlinfo_filepath)
これでEDINETコードリストを使って業種判定を行うための準備ができました。
続いて本題であるXBRL解析を行っていきます。 XBRLファイルの情報は1社ずつ取り扱うので、1社ずつクラスを作るようにします。 大量の企業の情報をいじる場合、不都合があるかもですが 扱いやすいようにしておきます。
Taxsonomyの一覧と和名リストを作ればテンプレートのように情報を追加していけるかと思います。
まずは、Arelleを扱うためこの用に書きました。
from arelle import ModelManager
from arelle import Cntlr
class CompanyData:
edinet_company_info_list = []
edinet_code = "" # EDINETCODE
company_name_jp = "" # 企業名
industry_code = "" # 業種
DilutedEarningsPerShareSummaryOfBusinessResults = ""#潜在株式調整後1株当たり当期純利益
EquityToAssetRatioSummaryOfBusinessResults = ""#自己資本比率
model_xbrl =""
def __init__(self,xbrl_file):
ctrl = Cntlr.Cntlr()
model_manager = ModelManager.initialize(ctrl)
self.model_xbrl = model_manager.load(xbrl_file)
業種を取得する場合このように書きます。 EdinetCodeとEDINETコードリストのCSVにある情報を紐づけて変数に格納します。
def setCompanyInfo(self,edinet_info_list):
for fact in self.model_xbrl.facts:
if fact.concept.qname.localName == 'EDINETCodeDEI':
self.edinet_code = fact.value
for code_name in edinet_info_list:
if code_name[0] == self.edinet_code:
self.industry_code = code_name[1]
break
企業名と自己資本比率を取得したい場合はこんなふうにかけます。
def setCompanyInfo(self,edinet_info_list):
for fact in self.model_xbrl.facts:
# print(fact.concept.qname.localName,fact.value)
if fact.concept.qname.localName == 'EDINETCodeDEI':
self.edinet_code = fact.value
for code_name in edinet_info_list:
if code_name[0] == self.edinet_code:
self.industry_code = code_name[1]
break
elif fact.concept.qname.localName == 'CompanyNameCoverPage': #企業名
self.company_name_jp = fact.value
これで概ね情報の取得方法は確立できました。 ゲット関数を書いてあげたら取得もできるかと。
def getCompanyName(self):
return self.company_name_jp
確認用にいくつか取得するデータを増やしてみたのがこのクラスです。
class CompanyData:
edinet_company_info_list = []
edinet_code = "" # EDINETCODE
company_name_jp = "" # 企業名
industry_code = "" # 業種
DilutedEarningsPerShareSummaryOfBusinessResults = ""#潜在株式調整後1株当たり当期純利益
EquityToAssetRatioSummaryOfBusinessResults = ""#自己資本比率
model_xbrl =""
def __init__(self,xbrl_file):
ctrl = Cntlr.Cntlr()
model_manager = ModelManager.initialize(ctrl)
self.model_xbrl = model_manager.load(xbrl_file)
def setCompanyInfo(self,edinet_info_list):
for fact in self.model_xbrl.facts:
# print(fact.concept.qname.localName,fact.value)
if fact.concept.qname.localName == 'EDINETCodeDEI':
self.edinet_code = fact.value
for code_name in edinet_info_list:
if code_name[0] == self.edinet_code:
self.industry_code = code_name[1]
break
elif fact.concept.qname.localName == 'CompanyNameCoverPage': #企業名
self.company_name_jp = fact.value
elif fact.concept.qname.localName == 'CapitalStockSummaryOfBusinessResults':#資本金
self.CapitalStockSummaryOfBusinessResults = fact.value
elif fact.concept.qname.localName == 'DilutedEarningsPerShareSummaryOfBusinessResults': #自己資本比率
self.DilutedEarningsPerShareSummaryOfBusinessResults = fact.value
elif fact.concept.qname.localName == 'EquityToAssetRatioSummaryOfBusinessResults': #
self.EquityToAssetRatioSummaryOfBusinessResults = fact.value
def getCompanyName(self):
return self.company_name_jp
def getIndastoryCode(self):
return self.industry_code
def getCompanyInfo(self):
return [self.edinet_code,self.industry_code,self.company_name_jp]
def getBusinessResult(self):
return self.DilutedEarningsPerShareSummaryOfBusinessResults
def getCapitalStockSummaryOfBusinessResults(self):
return self.CapitalStockSummaryOfBusinessResults
def getSummary(self):
return self.EquityToAssetRatioSummaryOfBusinessResults
EDINETの全体の情報を考えると全然足りませんが、要領は掴めたと思います。
完成したコード
import os
import zipfile
from arelle import ModelManager
from arelle import Cntlr
import pandas as pd
from pathlib import Path
import glob
class CompanyData:
edinet_company_info_list = []
edinet_code = "" # EDINETCODE
company_name_jp = "" # 企業名
industry_code = "" # 業種
DilutedEarningsPerShareSummaryOfBusinessResults = ""#潜在株式調整後1株当たり当期純利益
EquityToAssetRatioSummaryOfBusinessResults = ""#自己資本比率
model_xbrl =""
def __init__(self,xbrl_file):
ctrl = Cntlr.Cntlr()
model_manager = ModelManager.initialize(ctrl)
self.model_xbrl = model_manager.load(xbrl_file)
def setCompanyInfo(self,edinet_info_list):
for fact in self.model_xbrl.facts:
# print(fact.concept.qname.localName,fact.value)
if fact.concept.qname.localName == 'EDINETCodeDEI':
self.edinet_code = fact.value
for code_name in edinet_info_list:
if code_name[0] == self.edinet_code:
self.industry_code = code_name[1]
break
elif fact.concept.qname.localName == 'CompanyNameCoverPage': #企業名
self.company_name_jp = fact.value
elif fact.concept.qname.localName == 'DilutedEarningsPerShareSummaryOfBusinessResults': #自己資本比率
self.DilutedEarningsPerShareSummaryOfBusinessResults = fact.value
elif fact.concept.qname.localName == 'EquityToAssetRatioSummaryOfBusinessResults': #
self.EquityToAssetRatioSummaryOfBusinessResults = fact.value
def getCompanyName(self):
return self.company_name_jp
def getIndastoryCode(self):
return self.industry_code
def getCompanyInfo(self):
return [self.edinet_code,self.industry_code,self.company_name_jp]
def getBusinessResult(self):
return self.DilutedEarningsPerShareSummaryOfBusinessResults
def getSummary(self):
return self.EquityToAssetRatioSummaryOfBusinessResults
def makeEdinetCompInfoList(edinetcodedlinfo_filepath):
edinet_info = pd.read_csv(edinetcodedlinfo_filepath, skiprows=1,
encoding='cp932')
edinet_info = edinet_info[["EDINETコード", "提出者業種"]]
edinet_info_list = edinet_info.values.tolist()
return edinet_info_list
def main():
# ZIPファイルのパス
zip_file_path = 'S100FFK6_有価証券報告書_株式会社 クボタ.zip'
# 一時フォルダを作成
temp_dir = 'temp'
os.makedirs(temp_dir, exist_ok=True)
# ZIPファイルを一時フォルダに展開
with zipfile.ZipFile(zip_file_path, 'r') as zip_file:
zip_file.extractall(temp_dir)
xbrl_file = glob.glob(temp_dir+'/**/PublicDoc/*.xbrl')[0]
# print(files[0])
# xbrl_file = getXBRLFilePath(temp_dir)
kubota = CompanyData(xbrl_file)
edinetcodedlinfo_filepath = '.\\EdinetcodeDlInfo.csv'
edinet_info_list = makeEdinetCompInfoList(edinetcodedlinfo_filepath)
kubota.setCompanyInfo(edinet_info_list)
print('会社名',kubota.getCompanyName())
print('資本金',kubota.getBusinessResult())
print('潜在株式調整後1株当たり当期純利益',kubota.getBusinessResult())
print('自己資本比率',kubota.getSummary())
if __name__ == "__main__":
main()
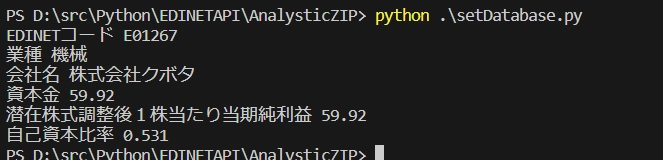
結果
このように企業名と資本金と自己資本比率と、当期純利益が取得できました。

まとめ
ひとまず、XBRLの解析し情報の取得ができました。 これを使って株選びを支援するプログラムを書こうと思うと、取得するデータ項目と、複数企業、4半期、過去数年分のデータを取り込んでいく必要があります。 まだまだ先は長いですが少しずつやっていきましょう。
個人的にやりたいのは、割安そうな株を探すのに使いたいんですよね。 業種別で理論株価を一覧にして、現在の株価との乖離を求めて銘柄を選びたいんですよ。 そこに、自己資本比率や、1株あたりの純利益の情報、四半期毎の売上高の増加率を加味してあげたら
サルがダーツの矢を投げて選ぶようなギャンブル的な株投資から、勝てる確率を上げることができるんじゃないかと考えています。
ある程度、情報取得ができて並べることができたら Webアプリとして扱いやすくするのか、院生の頃に買った確率・統計の本を読み直し実装していくのかなど、やることは沢山ありますが、ゆっくり作っていきましょう。