EDINET APIを用いて企業情報を取得するPythonコードを書いた。

はじめに
株で大損しました。反省点も多々あるのですがやはり1番大きなところは、みんかぶなどの情報サイトだけで銘柄選びをしていたという点にあります。
もちろん株のプロが選んでいるため素人の私があれこれ言うよりも情報は正しいものの、いつの情報を参考にしているのかなど不透明な部分も多くあります。
自分の大切な資産を他人に委ねる事自体間違えていたと言わざるをえないわけです。 必要な情報は自分の目で確認して納得してから取引すべきなのです。
というわけで今回は現金に直結する可能性があるため熱量が違います。
金融庁が公開しているEDINET APIから各企業が登録している有価証券報告書などの業績記録を取得できるように進めましょう。
先行きは長いのですが、まずはEDINETが提供している2つのAPIをリクエストするところまでを行います。
手法
まずは一括取得ようにサクッと動くものを用意したいため、Pythonで試作品を作ります。 もしサーバ等で運用できる状態になれば、GolangやRustで書き直そうかと考えています。
書類一覧 API
リクエストURLの作成
このAPIで登録された書類の有無を確認し、書類取得APIで必要な書類を取得するのが一連の流れになります。
基本的な情報は、EDINET API仕様書を読めば書いています。 REST APIを叩いて情報を取得するだけのプログラムになりますので、まずはURLを作成します。
URLに含めるパラメータはこのとおりです。
ベースURL
https://api.edinet-fsa.go.jp/api/v2/documents.json
リクエストパラメータ例
?date=2023-04-01&type=2&Subscription-Key=ZZZ…ZZZ
詳細な中身はAPI仕様書に書いてあるとおりです。
| パラメータ | 概要 |
|---|---|
| date | YYYY-MMDD形式 |
| type | 2 書類及びメタデータ取得 |
| Subscription-Key | APIキー |
APIキーの取得は過去の記事で解説済みのためそちらを参照ください。 EDINET API v2に登録して株式関連書類をGETしよう
日付は期間指定ができないため、1日ずつ要求する必要があるようです。 期間指定した日付を元に、要求するREST APIを作成する関数を準備します。
応答はURLをそのままリスト形式で返します。
def create_rest_urls(base_url, start, end, data_type, subscription_key):
# 文字列から日付オブジェクトを生成
start_date = datetime.strptime(start, "%Y-%m-%d")
end_date = datetime.strptime(end, "%Y-%m-%d")
urls = []
# 指定された期間内の日付ごとにURLを生成
current_date = start_date
while current_date <= end_date:
params = {
"date": current_date.strftime("%Y-%m-%d"),
"type": data_type,
"Subscription-Key": subscription_key
}
url_with_params = base_url +".json"+ "?" + "&".join(f"{key}={value}" for key, value in params.items())
urls.append(url_with_params)
current_date += timedelta(days=1)
return urls
def main():
# 使用例
base_url = "https://api.edinet-fsa.go.jp/api/v2/documents"
start = "2022-05-01"
end = "2023-05-12"
data_type = "2"
subscription_key = "APIキー"
urls = create_rest_urls(base_url, start, end, data_type, subscription_key)
for url in urls:
print(url)
if __name__ == "__main__":
main()
結果
こんな感じでURL一覧が取得できます。 あとはこのURLを連続でしばいて行くだけです。 一応それっぽいAPIキーを入れてますがダミーですのでエラーが帰ってきます。
省略
https://api.edinet-fsa.go.jp/api/v2/documents.json?date=2023-05-06&type=2&Subscription-Key=sakjwhjeujnfkjansvkjahsakjhfsajkh
https://api.edinet-fsa.go.jp/api/v2/documents.json?date=2023-05-07&type=2&Subscription-Key=sakjwhjeujnfkjansvkjahsakjhfsajkh
https://api.edinet-fsa.go.jp/api/v2/documents.json?date=2023-05-08&type=2&Subscription-Key=sakjwhjeujnfkjansvkjahsakjhfsajkh
https://api.edinet-fsa.go.jp/api/v2/documents.json?date=2023-05-09&type=2&Subscription-Key=sakjwhjeujnfkjansvkjahsakjhfsajkh
https://api.edinet-fsa.go.jp/api/v2/documents.json?date=2023-05-10&type=2&Subscription-Key=sakjwhjeujnfkjansvkjahsakjhfsajkh
https://api.edinet-fsa.go.jp/api/v2/documents.json?date=2023-05-11&type=2&Subscription-Key=sakjwhjeujnfkjansvkjahsakjhfsajkh
https://api.edinet-fsa.go.jp/api/v2/documents.json?date=2023-05-12&type=2&Subscription-Key=sakjwhjeujnfkjansvkjahsakjhfsajkh
書類一覧APIのJSONを取得する
作成したREST APIを叩くとJSONが取得できます。 このJSONを解析しClassに詰め込み利用しやすい形に整形します。
Classに詰め込んで取得するようにします。 新しくファイルを作成してください。ファイル名は好きなので良いですが、JSON2DocumentList.pyとしました。
from dataclasses import dataclass
from typing import Optional, List
@dataclass
class Parameter:
date: str
type: str
@dataclass
class Result:
seqNumber: int
docID: str
edinetCode: str
secCode: Optional[str]
JCN: str
filerName: str
fundCode: Optional[str]
ordinanceCode: str
formCode: str
docTypeCode: str
periodStart: Optional[str]
periodEnd: Optional[str]
submitDateTime: str
docDescription: str
issuerEdinetCode: Optional[str]
subjectEdinetCode: Optional[str]
subsidiaryEdinetCode: Optional[str]
currentReportReason: Optional[str]
parentDocID: Optional[str]
opeDateTime: Optional[str]
withdrawalStatus: str
docInfoEditStatus: str
disclosureStatus: str
xbrlFlag: str
pdfFlag: str
attachDocFlag: str
englishDocFlag: str
csvFlag: str
legalStatus: str
@dataclass
class Metadata:
title: str
parameter: Parameter
resultset: dict
processDateTime: str
status: str
message: str
@dataclass
class ApiResponse:
metadata: Metadata
results: List[Result]
mainを読んでいるファイルにこのような関数を作り、REST APIのURLにリクエストを行い、応答のJSONを取得し、先程定義したClassに詰め込む処理を書いていきます。
def fetch_api_data(api_url: str) -> Optional[ApiResponse]:
"""
REST APIを叩いてJSONを取得し、成功した場合にApiResponseクラスに詰め込む関数
:param api_url: REST APIのURL
:return: ApiResponseのインスタンス、またはエラーの場合はNone
"""
try:
response = requests.get(api_url)
response.raise_for_status() # 200 OK以外の場合は例外を発生させる
# JSONをApiResponseクラスに変換
data = response.json()
api_response = ApiResponse(
metadata=Metadata(
title=data["metadata"]["title"],
parameter=Parameter(**data["metadata"]["parameter"]),
resultset=data["metadata"]["resultset"],
processDateTime=data["metadata"]["processDateTime"],
status=data["metadata"]["status"],
message=data["metadata"]["message"]
),
results=[Result(**result) for result in data["results"]]
)
return api_response
except requests.RequestException as e:
print(f"API request failed: {e}")
return None
取り急ぎ結果確認用に、値取得用するための関数を定義しておきす。
def extract_docID_and_filerName(api_response: ApiResponse):
extracted_data = [(result.docID, result.filerName) for result in api_response.results]
return extracted_data
呼び出す関数はこんな感じです。実行すると2023/05/01に更新された書類一覧が取得できます。
def main():
# 使用例
base_url = "https://api.edinet-fsa.go.jp/api/v2/documents"
start = "2023-05-01"
end = "2023-05-01"
data_type = "2"
subscription_key = "sjkafhgakjnfvkjnsadvkjnsdkj"
urls = create_rest_urls(base_url, start, end, data_type, subscription_key)
for url in urls:
# print(url)
response_data = fetch_api_data(url)
if response_data:
data_list = extract_docID_and_filerName(response_data)
for doc_id, filer_name in data_list:
print(f"docID: {doc_id}, filerName: {filer_name}")
else:
print("Failed to fetch data from the API.")
結果
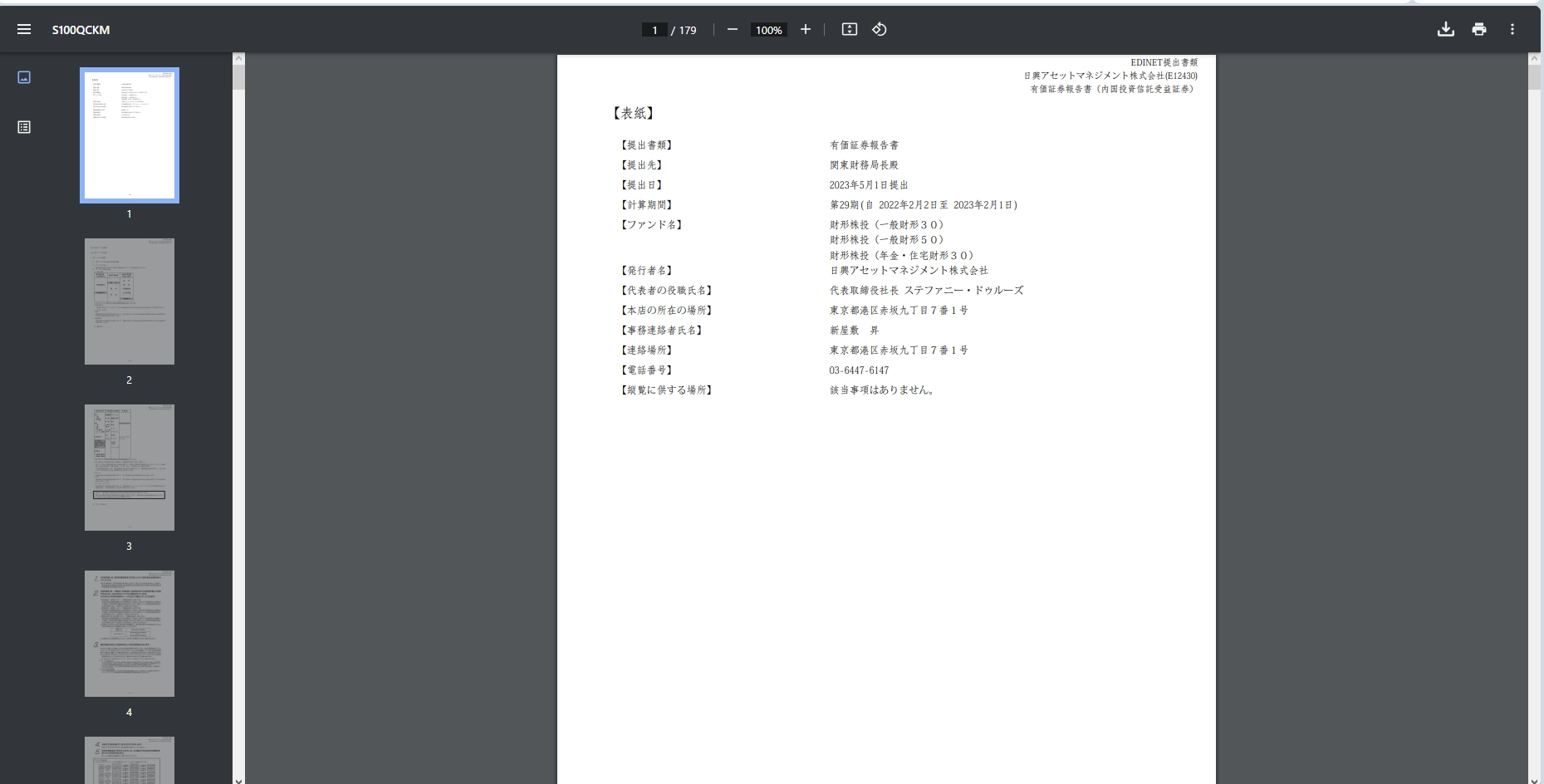
docID: S100QCKM, filerName: 日興アセットマネジメント株式会社
docID: S100QNDD, filerName: 明治安田アセットマネジメント株式会社
docID: S100QCKL, filerName: 日興アセットマネジメント株式会社
docID: S100QLM3, filerName: 三井住友DSアセットマネジメント株式会社
docID: S100QN0O, filerName: SOMPOアセットマネジメント株式会社
.... 省略
CSVFLAGの有無を確認する
情報としてはすでにClassに入っているので必要な情報を取り出していきましょう。 次のステップでCSVを一括取得していくので関数を追加します。
def extract_csvFlag_documents(api_response: ApiResponse) -> List[Tuple[str, str, str, str]]:
"""
csvFlagが1のドキュメントの情報を抜き出す関数
:param api_response: ApiResponseのインスタンス
:return: docID, submitDateTime, docDescription, filerName のタプルのリスト
"""
return [(result.docID, result.submitDateTime, result.docDescription, result.filerName)
for result in api_response.results if result.csvFlag == '1']
response_data = fetch_api_data(url)
if response_data:
extracted_data = extract_csvFlag_documents(response_data)
for doc_id, submit_time, description, filer_name in extracted_data:
print(f"docID: {doc_id}, submitDateTime: {submit_time}, docDescription: {description}, filerName: {filer_name}")
呼び出しはこのような感じでどうぞ。
csvflagがあるのでここが1即ち、CSVファイルが存在するものを取得できました。
ocID: S100QOCY, submitDateTime: 2023-05-01 10:56, docDescription: 訂正報告書(大量保有報告書・変更報告書), filerName: 高橋 宗敏
docID: S100QOAT, submitDateTime: 2023-05-01 11:01, docDescription: 変更報告書, filerName: 中村 義巳
docID: S100QMRQ, submitDateTime: 2023-05-01 11:03, docDescription: 発行登録書(株券、社債券等), filerName: 株式会社電通グループ
docID: S100QNT5, submitDateTime: 2023-05-01 11:03, docDescription: 有価証券報告書(内国信託受益証券等)-第2期(2022/08/17-2023/02/16), filerName: 三井住友信託銀行株式会社
docID: S100QOD7, submitDateTime: 2023-05-01 11:15, docDescription: 訂正報告書(大量保有報告書・変更報告書), filerName: 株式会社ダイコーホールディングスグループ
docID: S100QOCX, submitDateTime: 2023-05-01 11:17, docDescription: 訂正報告書(大量保有報告書・変更報告書), filerName: 株式会社ダイコーホールディングスグループ
docID: S100QNQD, submitDateTime: 2023-05-01 11:26, docDescription: 有価証券報告書(内国信託受益証券等)-第1期(2022/07/28-2023/02/15), filerName: 三井住友信託銀行株式会社
docID: S100QNN6, submitDateTime: 2023-05-01 11:33, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QOD2, submitDateTime: 2023-05-01 11:35, docDescription: 訂正報告書(大量保有報告書・変更報告書), filerName: 高橋 宗敏
docID: S100QNLO, submitDateTime: 2023-05-01 11:36, docDescription: 大量保有報告書, filerName: 株式会社フラクタル・ビジネス
docID: S100QNWO, submitDateTime: 2023-05-01 11:38, docDescription: 変更報告書, filerName: 合同会社インバウンドインベストメント
docID: S100QNN9, submitDateTime: 2023-05-01 11:38, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNNC, submitDateTime: 2023-05-01 11:43, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNNG, submitDateTime: 2023-05-01 11:48, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNNK, submitDateTime: 2023-05-01 11:54, docDescription: 大量保有報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNNM, submitDateTime: 2023-05-01 11:59, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QOCU, submitDateTime: 2023-05-01 12:00, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: 株式会社コマースOneホールディングス
docID: S100QNNO, submitDateTime: 2023-05-01 12:06, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNNQ, submitDateTime: 2023-05-01 12:13, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNNS, submitDateTime: 2023-05-01 12:19, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QOD5, submitDateTime: 2023-05-01 12:21, docDescription: 大量保有報告書, filerName: 株式会社プレンティー
docID: S100QODL, submitDateTime: 2023-05-01 12:23, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: 株式会社 桜井製作所
docID: S100QNNX, submitDateTime: 2023-05-01 12:24, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNO1, submitDateTime: 2023-05-01 12:30, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNO3, submitDateTime: 2023-05-01 12:35, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QODO, submitDateTime: 2023-05-01 12:43, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: 株式会社イボキン
docID: S100QNO4, submitDateTime: 2023-05-01 12:44, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNO5, submitDateTime: 2023-05-01 12:48, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNO8, submitDateTime: 2023-05-01 12:53, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNO9, submitDateTime: 2023-05-01 12:59, docDescription: 大量保有報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QODF, submitDateTime: 2023-05-01 13:03, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: センコン物流株式会社
docID: S100QOCN, submitDateTime: 2023-05-01 13:04, docDescription: 大量保有報告書(特例対象株券等), filerName: オービス・インベストメント・マネジメント・リミテッド
docID: S100QNOA, submitDateTime: 2023-05-01 13:05, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QODH, submitDateTime: 2023-05-01 13:10, docDescription: 臨時報告書, filerName: 株式会社リベルタ
docID: S100QNOD, submitDateTime: 2023-05-01 13:13, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNOF, submitDateTime: 2023-05-01 13:20, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNOG, submitDateTime: 2023-05-01 13:24, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QO83, submitDateTime: 2023-05-01 13:25, docDescription: 四半期報告書-第66期第1四半期(2022/12/21-2023/03/20), filerName: 東邦 レマック株式会社
docID: S100QNOI, submitDateTime: 2023-05-01 13:30, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNHA, submitDateTime: 2023-05-01 13:34, docDescription: 変更報告書, filerName: 谷郷 元昭
docID: S100QNOJ, submitDateTime: 2023-05-01 13:36, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNOL, submitDateTime: 2023-05-01 13:41, docDescription: 大量保有報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNOM, submitDateTime: 2023-05-01 13:48, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QNOO, submitDateTime: 2023-05-01 13:52, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QO7E, submitDateTime: 2023-05-01 13:53, docDescription: 訂正自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: 株式会社酉島製作所
docID: S100QO56, submitDateTime: 2023-05-01 13:58, docDescription: 四半期報告書-第140期第2四半期(2023/01/01-2023/03/31), filerName: ホウライ株式会社
docID: S100QNOP, submitDateTime: 2023-05-01 14:01, docDescription: 変更報告書(特例対象株券等), filerName: 株式会社三菱UFJフィナンシャル・グループ
docID: S100QO2K, submitDateTime: 2023-05-01 14:21, docDescription: 変更報告書, filerName: 黒木 勉
docID: S100QOEJ, submitDateTime: 2023-05-01 14:37, docDescription: 変更報告書, filerName: 黒木 勉
docID: S100QO31, submitDateTime: 2023-05-01 14:41, docDescription: 変更報告書, filerName: SMBC日興証券株式会社
docID: S100QOCL, submitDateTime: 2023-05-01 15:00, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: テクノプロ・ホールディングス株式会社
docID: S100QNB6, submitDateTime: 2023-05-01 15:00, docDescription: 大量保有報告書, filerName: Long Corridor Asset Management Limited
docID: S100QOF3, submitDateTime: 2023-05-01 15:00, docDescription: 臨時報告書, filerName: 株式会社JDSC
docID: S100QODC, submitDateTime: 2023-05-01 15:03, docDescription: 変更報告書, filerName: マイルストーン・キャピタル・マネジメント株式会社
docID: S100QOF4, submitDateTime: 2023-05-01 15:07, docDescription: 有価証券届出書(組込方式), filerName: トミタ電機株式会社
docID: S100QOFC, submitDateTime: 2023-05-01 15:11, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: トレイダーズホールディングス株式会社
docID: S100QOFI, submitDateTime: 2023-05-01 15:18, docDescription: 臨時報告書, filerName: 株式会社GENOVA
docID: S100QOBT, submitDateTime: 2023-05-01 15:18, docDescription: 変更報告書, filerName: ハンマックス・インベストメント・リミテッド
docID: S100QOFJ, submitDateTime: 2023-05-01 15:19, docDescription: 臨時報告書, filerName: 株式会社GENOVA
docID: S100QOE3, submitDateTime: 2023-05-01 15:20, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: 株式会社毎日コムネット
docID: S100QOB7, submitDateTime: 2023-05-01 15:25, docDescription: 訂正報告書(大量保有報告書・変更報告書), filerName: 米今 政臣
docID: S100QO6C, submitDateTime: 2023-05-01 15:27, docDescription: 臨時報告書, filerName: アジア開発キャピタル株式会社
docID: S100QOFK, submitDateTime: 2023-05-01 15:29, docDescription: 訂正公開買付届出書, filerName: 株式会社ハピネット
docID: S100QODR, submitDateTime: 2023-05-01 15:29, docDescription: 変更報告書, filerName: Nippon Opportunity Management LLC
docID: S100QOFL, submitDateTime: 2023-05-01 15:30, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: 株式会社ビーロット
docID: S100QO2J, submitDateTime: 2023-05-01 15:30, docDescription: 臨時報告書, filerName: アーキテクツ・スタジオ・ジャパン株式会社
docID: S100QO5G, submitDateTime: 2023-05-01 15:30, docDescription: 臨時報告書(内国特定有価証券), filerName: みずほ信託銀行株式会社
docID: S100QO8D, submitDateTime: 2023-05-01 15:30, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: 株式会社アールプランナー
docID: S100QOCS, submitDateTime: 2023-05-01 15:32, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: 株式会社インターアクション
docID: S100QOC3, submitDateTime: 2023-05-01 15:32, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: 日本国土開発株式会社
docID: S100QNT6, submitDateTime: 2023-05-01 15:34, docDescription: 変更報告書, filerName: エフィッシモ キャピタル マネージメント ピーティーイー エルティーディー(Effissimo Capital Management Pte Ltd)
docID: S100QOD1, submitDateTime: 2023-05-01 15:34, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: さくらインターネット株式会社
docID: S100QNTC, submitDateTime: 2023-05-01 15:39, docDescription: 変更報告書, filerName: エフィッシモ キャピタル マネージメント ピーティーイー エルティーディー(Effissimo Capital Management Pte Ltd)
docID: S100QOFF, submitDateTime: 2023-05-01 15:43, docDescription: 訂正報告書(大量保有報告書・変更報告書), filerName: 西武ハウス株式会社
docID: S100QOFW, submitDateTime: 2023-05-01 15:51, docDescription: 変更報告書, filerName: 森本 数馬
docID: S100QNTN, submitDateTime: 2023-05-01 15:51, docDescription: 変更報告書, filerName: エフィッシモ キャピタル マネージメント ピーティーイー エルティーディー(Effissimo Capital Management Pte Ltd)
docID: S100QHXE, submitDateTime: 2023-04-03 15:56, docDescription: 変更報告書, filerName: 株式会社バリスター
docID: S100QN6S, submitDateTime: 2023-04-25 15:36, docDescription: 変更報告書(短期大量譲渡), filerName: 株式会社バリスター
docID: S100QOG0, submitDateTime: 2023-05-01 15:56, docDescription: 臨時報告書, filerName: 山喜株式会社
docID: S100QOFZ, submitDateTime: 2023-05-01 15:56, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: 株式会社関通
docID: S100QNT3, submitDateTime: 2023-05-01 15:59, docDescription: 変更報告書, filerName: Evo Fund
docID: S100QOG3, submitDateTime: 2023-05-01 15:59, docDescription: 臨時報告書, filerName: 株式会社免疫生物研究所
docID: S100QO79, submitDateTime: 2023-05-01 16:00, docDescription: 臨時報告書, filerName: ラオックスホールディングス株式会社
docID: S100QO34, submitDateTime: 2023-05-01 16:00, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: 株式会社アイ・パートナーズフィナンシャル
docID: S100QOG7, submitDateTime: 2023-05-01 16:01, docDescription: 臨時報告書, filerName: インパクトホールディングス株式会社
docID: S100QOAM, submitDateTime: 2023-05-01 16:04, docDescription: 変更報告書, filerName: ライオントラスト・インベストメント・パートナーズ・エル・エル・ピー
docID: S100QOG8, submitDateTime: 2023-05-01 16:06, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: 株式会社ロコンド
docID: S100QO88, submitDateTime: 2023-05-01 16:07, docDescription: 四半期報告書-第72期第2四半期(2022/12/21-2023/03/20), filerName: マル サンアイ株式会社
docID: S100QNU0, submitDateTime: 2023-05-01 16:10, docDescription: 変更報告書, filerName: エフィッシモ キャピタル マネージメント ピーティーイー エルティーディー(Effissimo Capital Management Pte Ltd)
docID: S100QOFO, submitDateTime: 2023-05-01 16:12, docDescription: 訂正報告書(大量保有報告書・変更報告書), filerName: 株式会社合人社グループ
docID: S100QNUM, submitDateTime: 2023-05-01 16:13, docDescription: 変更報告書, filerName: エフィッシモ キャピタル マネージメント ピーティーイー エルティーディー(Effissimo Capital Management Pte Ltd)
docID: S100QOGC, submitDateTime: 2023-05-01 16:15, docDescription: 変更報告書, filerName: 3D Investment Partners Pte. Ltd.
docID: S100QNUS, submitDateTime: 2023-05-01 16:18, docDescription: 変更報告書, filerName: エフィッシモ キャピタル マネージメント ピーティーイー エルティーディー(Effissimo Capital Management Pte Ltd)
docID: S100QNV2, submitDateTime: 2023-05-01 16:21, docDescription: 変更報告書, filerName: エフィッシモ キャピタル マネージメント ピーティーイー エルティーディー(Effissimo Capital Management Pte Ltd)
docID: S100QNVE, submitDateTime: 2023-05-01 16:24, docDescription: 変更報告書, filerName: エフィッシモ キャピタル マネージメント ピーティーイー エルティーディー(Effissimo Capital Management Pte Ltd)
docID: S100QNWS, submitDateTime: 2023-05-01 16:29, docDescription: 変更報告書, filerName: 村井 智建
docID: S100QOFM, submitDateTime: 2023-05-01 16:30, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: MRT株式会社
docID: S100QOGB, submitDateTime: 2023-05-01 16:30, docDescription: 訂正自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: MRT株式会社
docID: S100QOEF, submitDateTime: 2023-05-01 16:50, docDescription: 臨時報告書, filerName: GMB株式会社
docID: S100QOED, submitDateTime: 2023-05-01 16:55, docDescription: 臨時報告書, filerName: GMB株式会社
docID: S100QOHN, submitDateTime: 2023-05-01 17:06, docDescription: 自己株券買付状況報告書(法24条の6第1項に基づくもの), filerName: カネコ種苗株式会社
書類取得API
ベースURL
https://api.edinet-fsa.go.jp/api/v2/documents/
リクエストパラメータ S1234567というのは先程取得した書類番号が入ります。
S1234567?type=1&Subscription-Key=ZZZ…ZZZ
CSVファイルの一括取得
先程の要領で取得用のREST URLを作成する関数を作りました。
def create_rest_urls_for_docs(base_url, doc_id,data_type, subscription_key):
# 各doc_idに対してURLを生成
params = {
"type": data_type,
"Subscription-Key": subscription_key
}
url_with_params = base_url+"/"+doc_id + "?" + "&".join(f"{key}={value}" for key, value in params.items())
return url_with_params
呼び出し元はこんな風に書くことができます。
data_type=1
for doc_id, submit_time, description, filer_name in extracted_data:
print(f"docID: {doc_id}, submitDateTime: {submit_time}, docDescription: {description}, filerName: {filer_name}")
apiurl = create_rest_urls_for_docs(base_url,doc_id,data_type,subscription_key)
try:
print(apiurl)
response = requests.get(apiurl)
time.sleep(0.5)
except requests.RequestException as e:
print(f"API request failed: {e}")
ファイルをDLする場合は、urllib.requestを使うと良いです。
import urllib.request
for doc_id, submit_time, description, filer_name in extracted_data:
print(f"docID: {doc_id}, submitDateTime: {submit_time}, docDescription: {description}, filerName: {filer_name}")
apiurl = create_rest_urls_for_docs(base_url,doc_id,data_type,subscription_key)
try:
print(apiurl)
save_name_path = "./"+doc_id+"_"+filer_name
urllib.request.urlretrieve(apiurl, save_name_path)
time.sleep(0.5)
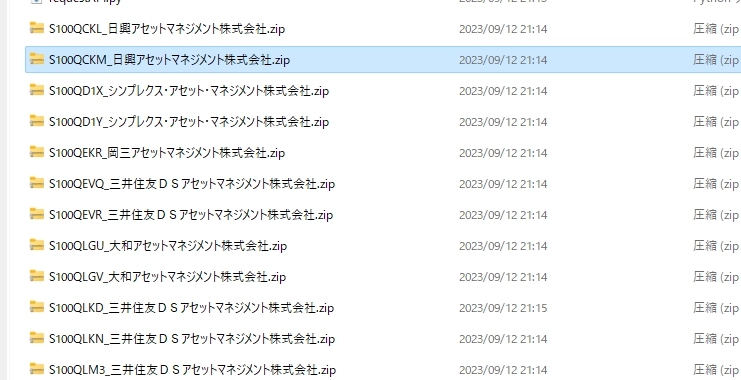
機能追加した全文
これまでのソフトだと、DLに失敗したらはじめからやり直しになってしまい非効率です。 そのため、まずDL用のURLを作成するスクリプトと、DL用のURLリストを元にダウンロードできるスクリプトの2つを用意しました。
DL用のスクリプトはマルチスレッドでかつ、プログレスバーも追加しています。
全文はこのとおりです
DLリンク作成スクリプト
データ定義用のファイル、JSON2DocumentList.py
from dataclasses import dataclass
from typing import Optional, List
@dataclass
class Parameter:
date: str
type: str
@dataclass
class Result:
seqNumber: int
docID: str
edinetCode: str
secCode: Optional[str]
JCN: str
filerName: str
fundCode: Optional[str]
ordinanceCode: str
formCode: str
docTypeCode: str
periodStart: Optional[str]
periodEnd: Optional[str]
submitDateTime: str
docDescription: str
issuerEdinetCode: Optional[str]
subjectEdinetCode: Optional[str]
subsidiaryEdinetCode: Optional[str]
currentReportReason: Optional[str]
parentDocID: Optional[str]
opeDateTime: Optional[str]
withdrawalStatus: str
docInfoEditStatus: str
disclosureStatus: str
xbrlFlag: str
pdfFlag: str
attachDocFlag: str
englishDocFlag: str
csvFlag: str
legalStatus: str
@dataclass
class Metadata:
title: str
parameter: Parameter
resultset: dict
processDateTime: str
status: str
message: str
@dataclass
class ApiResponse:
metadata: Metadata
results: List[Result]
実際にURLを取得するスクリプトはこちらです。
import csv
import threading
import time
import requests
from datetime import datetime, timedelta
from JSON2DocumentList import ApiResponse,Metadata,Result,Parameter
import requests
from typing import Optional
from typing import List, Tuple
import urllib.request
import os
base_url = "https://api.edinet-fsa.go.jp/api/v2/documents"
start = "2018-09-13"
end = "2023-09-14"
subscription_key = "APIキー"
docInfo ={'010':'有価証券通知書',
'020':'変更通知書(有価証券通知書)',
'030':'有価証券届出書',
'040':'訂正有価証券届出書',
'050':'届出の取下げ願い',
'060':'発行登録通知書',
'070':'変更通知書(発行登録通知書)',
'080':'発行登録書',
'090':'訂正発行登録書',
'100':'発行登録追補書類',
'110':'発行登録取下届出書',
'120':'有価証券報告書',
'130':'訂正有価証券報告書',
'135':'確認書',
'136':'訂正確認書',
'140':'四半期報告書',
'150':'訂正四半期報告書',
'160':'半期報告書',
'170':'訂正半期報告書',
'180':'臨時報告書',
'190':'訂正臨時報告書',
'200':'親会社等状況報告書',
'210':'訂正親会社等状況報告書',
'220':'自己株券買付状況報告書',
'230':'訂正自己株券買付状況報告書',
'235':'内部統制報告書',
'236':'訂正内部統制報告書',
'240':'公開買付届出書',
'250':'訂正公開買付届出書',
'260':'公開買付撤回届出書',
'270':'公開買付報告書',
'280':'訂正公開買付報告書',
'290':'意見表明報告書',
'300':'訂正意見表明報告書',
'310':'対質問回答報告書',
'320':'訂正対質問回答報告書',
'330':'別途買付け禁止の特例を受けるための申出書',
'340':'訂正別途買付け禁止の特例を受けるための申出書',
'350':'大量保有報告書',
'360':'訂正大量保有報告書',
'370':'基準日の届出書',
'380':'変更の届出書'}
def write_to_csv(filename, data):
"""
データをCSVファイルに書き込む関数
"""
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["URL"]) # ヘッダー行
for row in data:
writer.writerow([row])
def read_from_csv(filename):
"""
CSVファイルからデータを読み込む関数
"""
with open(filename, 'r', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
next(reader) # ヘッダー行をスキップ
return [row[0] for row in reader]
def create_rest_urls(base_url, data_type):
# 文字列から日付オブジェクトを生成
start_date = datetime.strptime(start, "%Y-%m-%d")
end_date = datetime.strptime(end, "%Y-%m-%d")
urls = []
# 指定された期間内の日付ごとにURLを生成
current_date = start_date
while current_date <= end_date:
params = {
"date": current_date.strftime("%Y-%m-%d"),
"type": data_type,
"Subscription-Key": subscription_key
}
url_with_params = base_url +".json"+ "?" + "&".join(f"{key}={value}" for key, value in params.items())
urls.append(url_with_params)
current_date += timedelta(days=1)
return urls
def create_rest_urls_for_docs(base_url, doc_id,data_type):
# 各doc_idに対してURLを生成
params = {
"type": data_type,
"Subscription-Key": subscription_key
}
url_with_params = base_url+"/"+doc_id + "?" + "&".join(f"{key}={value}" for key, value in params.items())
return url_with_params
def requestEDINETAPI(url):
# Make the API request
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"Error {response.status_code}: {response.text}")
def fetch_api_data(api_url: str) -> Optional[ApiResponse]:
"""
REST APIを叩いてJSONを取得し、成功した場合にApiResponseクラスに詰め込む関数
:param api_url: REST APIのURL
:return: ApiResponseのインスタンス、またはエラーの場合はNone
"""
try:
response = requests.get(api_url)
response.raise_for_status() # 200 OK以外の場合は例外を発生させる
# JSONをApiResponseクラスに変換
data = response.json()
api_response = ApiResponse(
metadata=Metadata(
title=data["metadata"]["title"],
parameter=Parameter(**data["metadata"]["parameter"]),
resultset=data["metadata"]["resultset"],
processDateTime=data["metadata"]["processDateTime"],
status=data["metadata"]["status"],
message=data["metadata"]["message"]
),
results=[Result(**result) for result in data["results"]]
)
return api_response
except requests.RequestException as e:
print(f"API request failed: {e}")
return None
def extract_docID_and_filerName(api_response: ApiResponse):
"""
ApiResponse クラスのインスタンスから docID と filerName を取得する関数
:param api_response: ApiResponseのインスタンス
:return: docID と filerName のリストのタプル
"""
extracted_data = [(result.docID, result.filerName) for result in api_response.results]
return extracted_data
def extract_csvFlag_documents(api_response: ApiResponse) -> List[Tuple[str, str, str, str]]:
"""
csvFlagが1のドキュメントの情報を抜き出す関数
:param api_response: ApiResponseのインスタンス
:return: docID, submitDateTime, docDescription, filerName のタプルのリスト
"""
return [(result.docID, result.submitDateTime, result.docDescription, result.filerName,result.docTypeCode)
for result in api_response.results if result.csvFlag == '1']
state_file = "download_state.txt"
def load_last_downloaded_url():
# 状態ファイルが存在する場合、最後にダウンロードしたURLを読み込む
if os.path.exists(state_file):
with open(state_file, "r") as file:
return file.read().strip()
return None
def save_last_downloaded_url(url,url2):
# 最後にダウンロードしたURLを状態ファイルに保存
with open(state_file, "w") as file:
file.write(url)
def create_rest_document_urls(url):
response_data = fetch_api_data(url)
resulturls = []
if response_data:
extracted_data = extract_csvFlag_documents(response_data)
data_type = 1
for doc_id, submit_time, description, filer_name, docTypeCode in extracted_data:
apiurl = create_rest_urls_for_docs(base_url, doc_id, data_type)
if docTypeCode != None:
dic = docInfo[docTypeCode]
save_name_path = "./" + dic + "/" + doc_id + "_" + dic + "_" + filer_name + ".zip"
resulturls.append([docTypeCode,save_name_path,apiurl])
else:
print("WARNING::",docTypeCode,save_name_path,apiurl)
return resulturls
def main():
data_type = "2"
urls = create_rest_urls(base_url, data_type)
# URLの一覧をCSVに書き出す
write_to_csv("urls.csv", urls)
# CSVからURLを読み込む
urls_from_csv = read_from_csv("urls.csv")
# ドキュメントのダウンロード用のURLを作成
download_urls = []
for url in urls_from_csv:
print(url)
urlstemp = create_rest_document_urls(url)
for tmp in urlstemp:
download_urls.append(tmp)
# ダウンロード用のURLを新しいCSVに書き出す
write_to_csv("download_urls.csv", download_urls)
if __name__ == "__main__":
main()
DL用スクリプト
import csv
import os
import threading
import urllib.request
from tqdm import tqdm
# ダウンロード済みのファイルを記録するファイル名
DOWNLOADED_FILES_LIST = "downloaded_files.txt"
def read_csv_file(filename):
with open(filename, 'r', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
return [[item.replace("'", "") for item in row] for row in reader][1:]
def download_file(url, save_path, pbar):
save_path = save_path.strip() # 余分なスペースを取り除く
try:
if not os.path.exists(os.path.dirname(save_path)):
os.makedirs(os.path.dirname(save_path))
urllib.request.urlretrieve(url, save_path)
pbar.update(1)
return True
except Exception as e:
print(f"Floder {save_path} Error downloading {url}. Error: {e}")
return False
def download_files_threaded(data_subset, pbar, downloaded_files):
for doc_type, save_path, url in data_subset:
if doc_type == '120' and save_path not in downloaded_files:
success = download_file(url, save_path, pbar)
if success:
save_downloaded_file(save_path)
def load_downloaded_files():
if not os.path.exists(DOWNLOADED_FILES_LIST):
with open(DOWNLOADED_FILES_LIST, 'w', encoding='utf-8') as file:
pass # 新規ファイルを作成
with open(DOWNLOADED_FILES_LIST, 'r', encoding='utf-8') as file:
return set(file.read().splitlines())
def save_downloaded_file(filename):
with open(DOWNLOADED_FILES_LIST, 'a', encoding='utf-8') as file:
file.write(filename + "\n")
def main():
csv_data = read_csv_file("download_urls.csv")
downloaded_files = load_downloaded_files()
pbar = tqdm(total=len([row for row in csv_data if row[0] == '120']), desc="Downloading", ncols=100)
num_threads = 10
threads = []
data_subset_size = len(csv_data) // num_threads
for i in range(num_threads):
start_index = i * data_subset_size
end_index = (i + 1) * data_subset_size if i != num_threads - 1 else None # 最後のスレッドは残りのすべてを処理
thread = threading.Thread(target=download_files_threaded, args=(csv_data[start_index:end_index], pbar, downloaded_files))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
pbar.close()
if __name__ == "__main__":
main()
まとめ
かなり過剰な構成になりましたが、XBRLが入ったZipファイルが入手できるようになりました。



 amazon.co.jp
amazon.co.jp




