StableDiffusionを使って画像生成してみよう

はじめに
生成AIについては賛否ありますが、ゲームを作ったりデスクトップマスコットを作りたいなと思ったときに、この手のイラストがポンっと手に入るのは便利であるのも事実です。 新しいものはとりあえず使ってみようというスタンスではあるので、一度触ってみようかと思った次第です。 せっかくやるならローカルPCで動かしたいとも考えております。 そこそこ良いPCを組んだので頑張ってくれるんじゃないかと期待してはいます。
ただ、グラボはハイエンドでは無いんですよね…ミドルクラスのものを使っているので難しい気もしています。そのあたりも含め確認ということでやっていきます。
ちなみに私が使ってるグラボはこれです。
一時期中古7万とかいう値段ついてましたが、今は3万ぐらいに落ち着いてますね。 私が買ったときは新品4万ですね。確かなんか株で儲かって嬉しくなって買ったはずです。

 amazon.co.jp
amazon.co.jp
webUI版のStable-diffusionをDLする
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
適当なフォルダに置いてください。
webUIを起動する
Cloneしてきたファイルから、webui.batを起動します。 10分ぐらいかかるようなので放置で良いです。
pytorchなどをDLしているようです。
セットアップが完了すると、分かりづらいですがlocalhostで起動しているポート番号などが表示されます。
http://127.0.0.1:7860
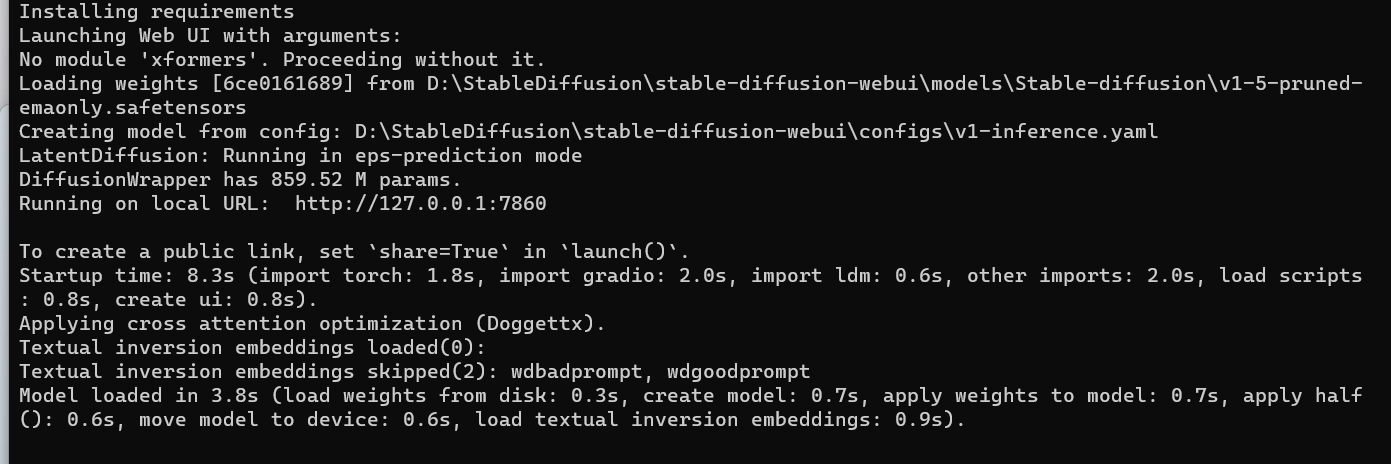
このURLを開くとWebUIが見れるようになっています。
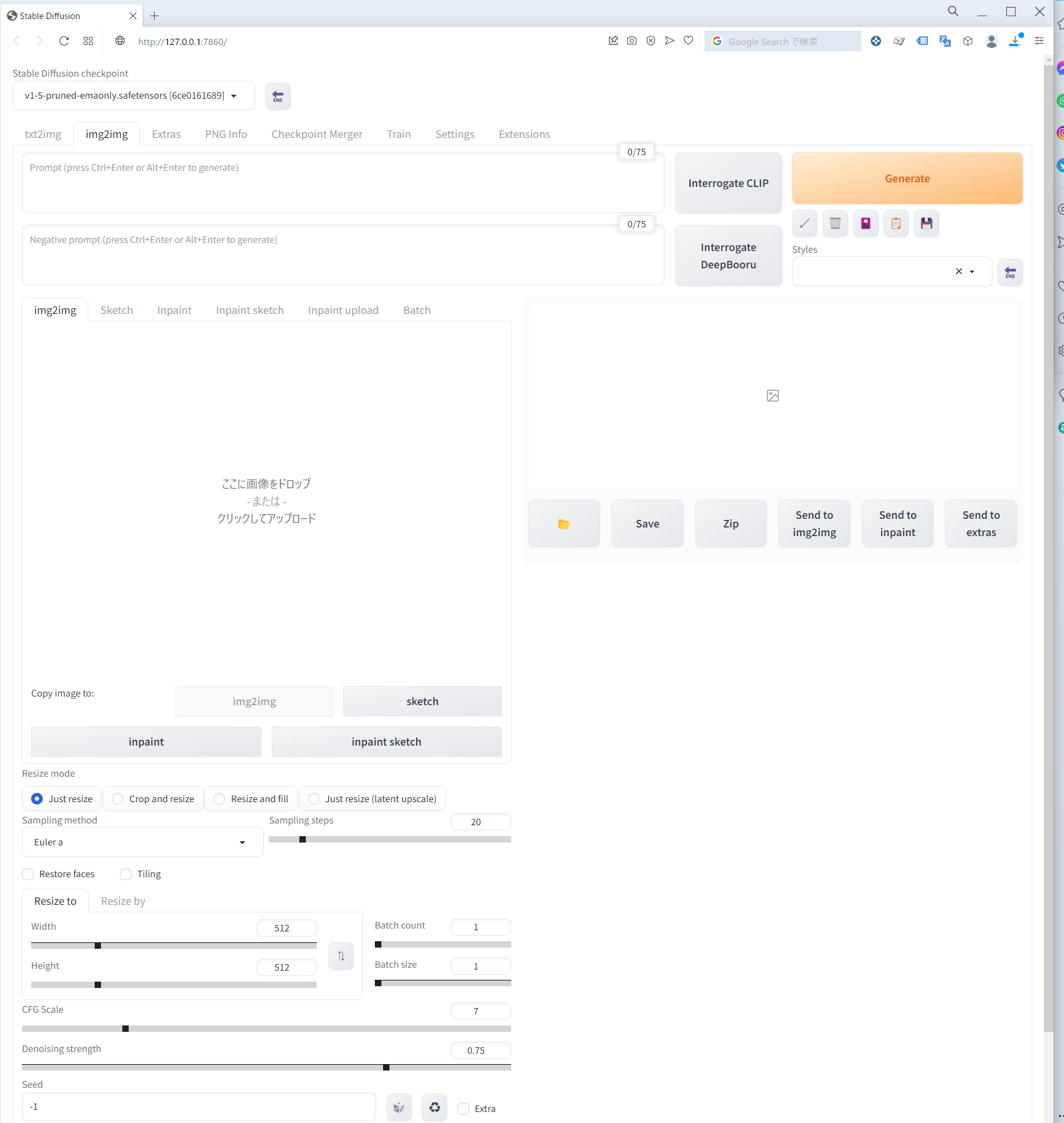
モデルをDLする
Hugging Face AI Communityとして有名どころです。こちらに多数のモデルが公開されています。
アニメイラストに強いモデルらしいです。 https://huggingface.co/waifu-diffusion/wd-1-5-beta3
こちらはStableDiffusionです。有名どころですね。
https://huggingface.co/stabilityai/stable-diffusion-2-1

Use it withからDLできます。 5GB近くあるのでのんびり待ちましょう。 うちのマンション未だに理論値最大100MBという糞回線マンションでこの手のファイルDLが非常に厳しい。
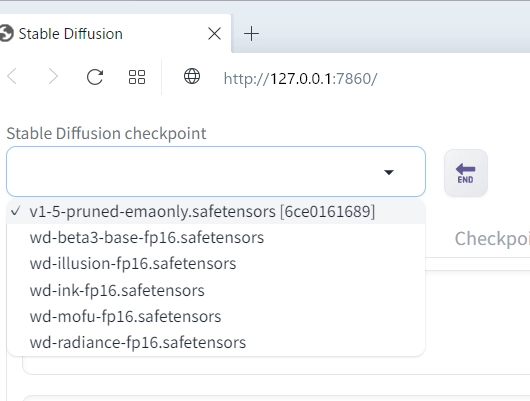
.safetensorsという拡張子のファイルは、StableDiffusionの下記フォルダに格納します。
.\stable-diffusion-webui\models\Stable-diffusion
うまく取り込むことができるとこのようにModelが追加されていることが確認できます。
GFPGANの追加
名前からして、敵対的ニューラルネットワークの亜種だと思います。 生成した画像から新しい画像を生成作業を繰り返し、より顔などの細部の作り込みを行うために使用できるようです。
https://github.com/TencentARC/GFPGAN
青字にした部分から.phtファイルをDLします。

DLしたファイルはWebUI.batと同一階層に保存します。
.\StableDiffusion\stable-diffusion-webui
これで準備完了です。 WebUI.batを起動します。
プロンプトの作成
プロンプトでいい感じに出力できるか左右されるようなので書いていきます。 正直全然ノウハウが無いので、ネット上に転がる検索結果を参考に作っていきます。
こういうのは検索機能が盛り込まれたBing Chatのほうが適していそうなので依頼してみますか。
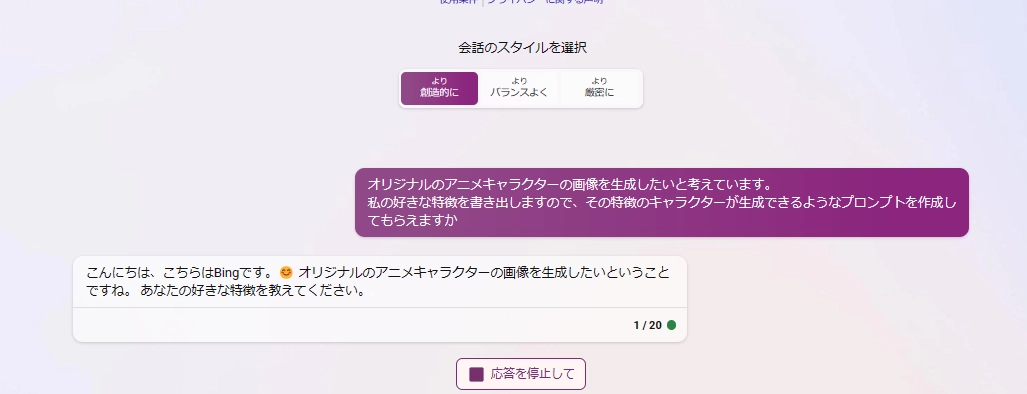
僕の考える最強の美少女キャラクターを書き出してもらおうか。
初めて知ったのですがBingAIにも画像生成機能が追加されているようです。 これはプロンプト作成に行ったやり取りの一例です。
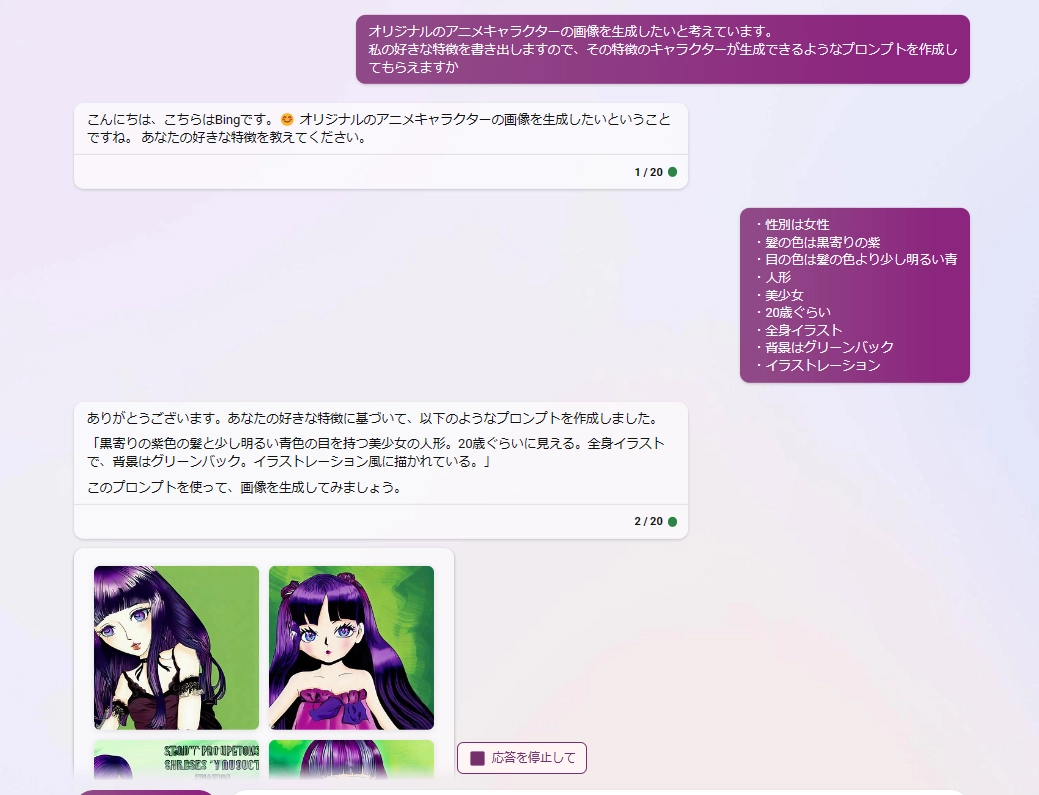
中々味のある画像を出力してくれました。これはこれで良いのですが今回の用途には合わないので修正していきます。
なんかネットでよく使われてる条件を追加してもらって、プロンプトの英語化を行います。
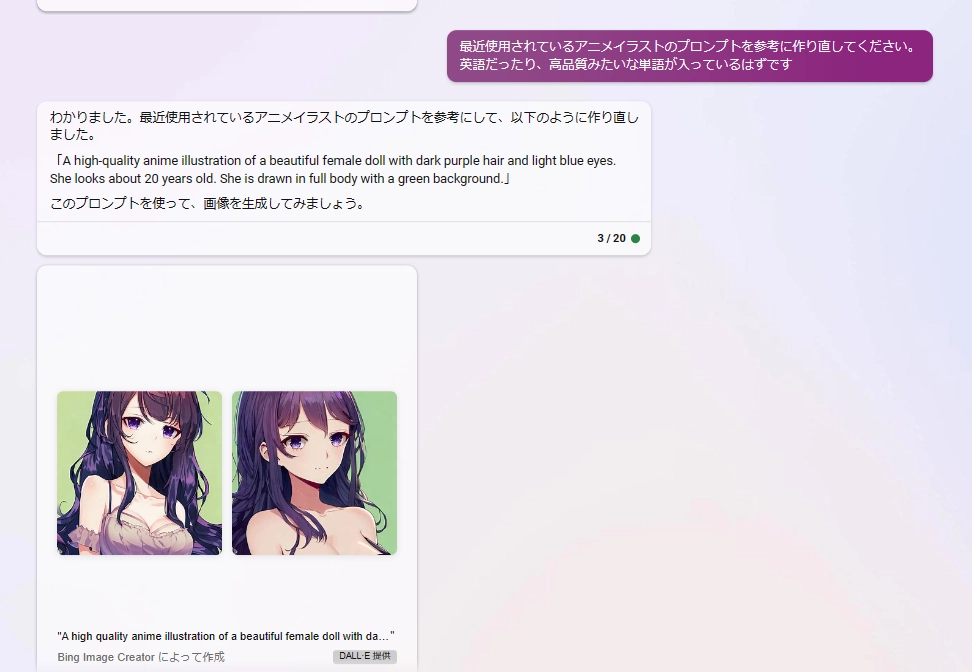
かなり良くなりました。
今回はVtuber用の画像として使いまわしたいので、正面画像の条件を追加します。
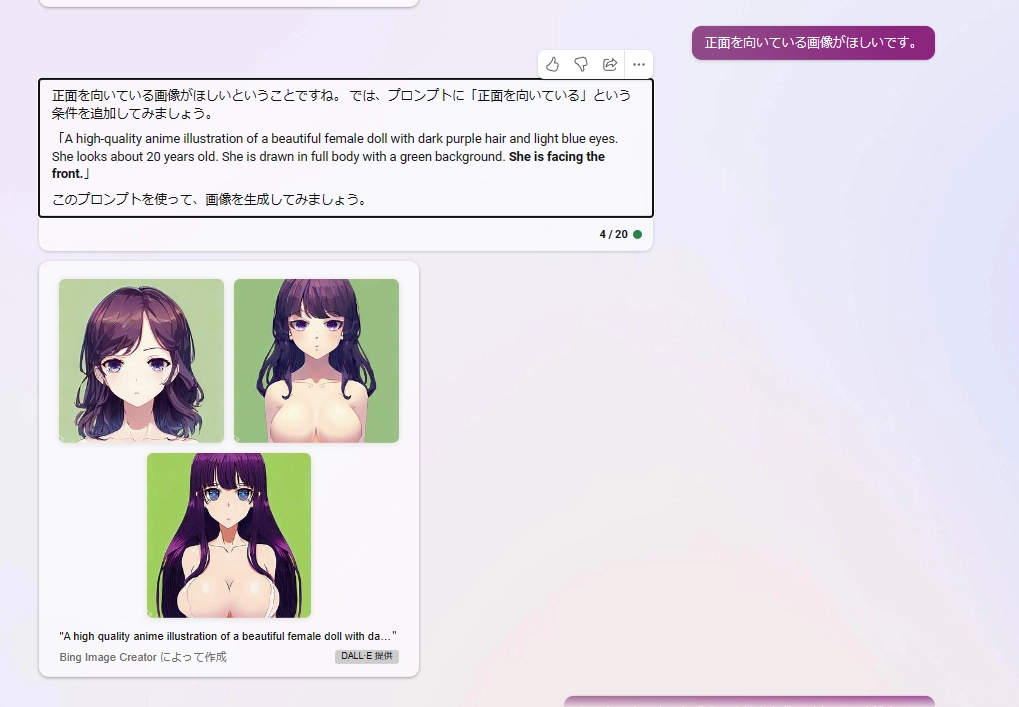
服が消えました。みんな正面顔だと服を描かないということでしょう。私にはわかります。 続けましょう。
イキイキとした感じのキャラクターを作って欲しいなと思ったので条件を追加します。
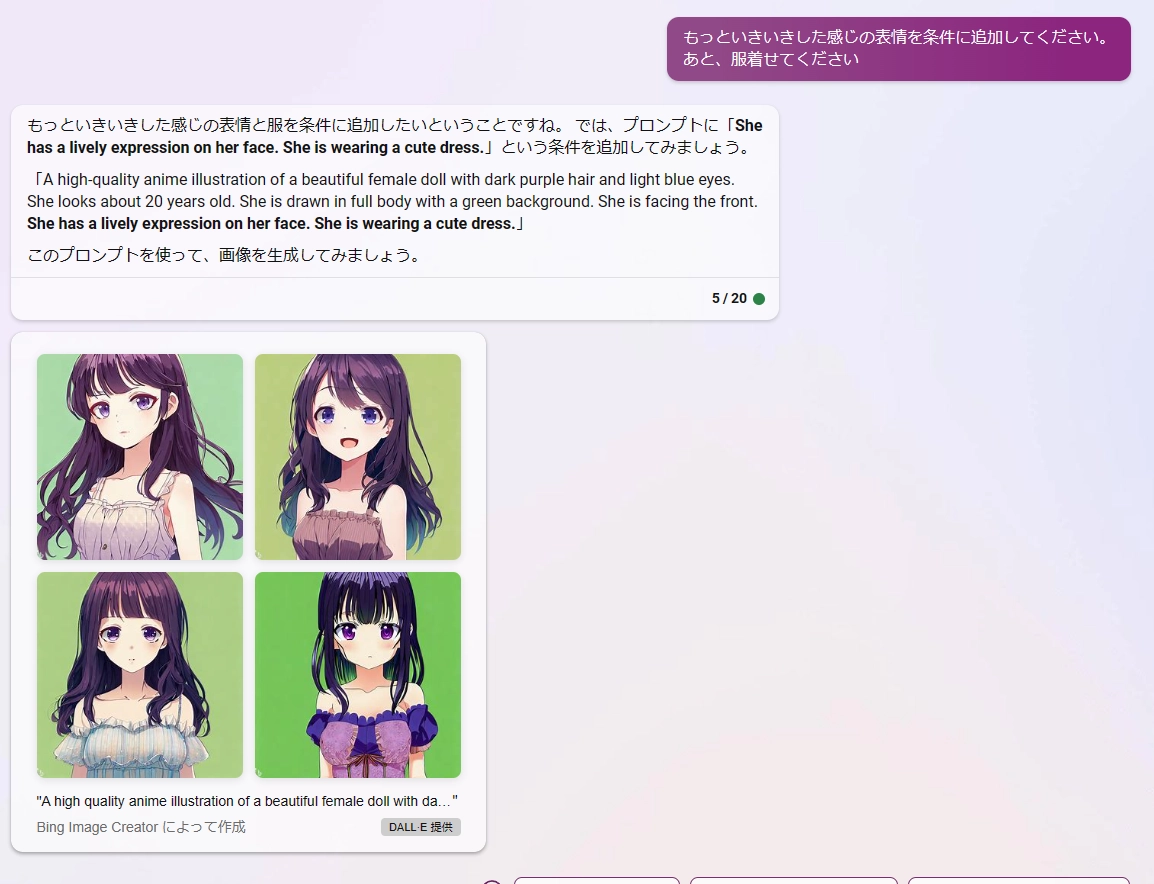
この子は中々私の好みをついてますね。
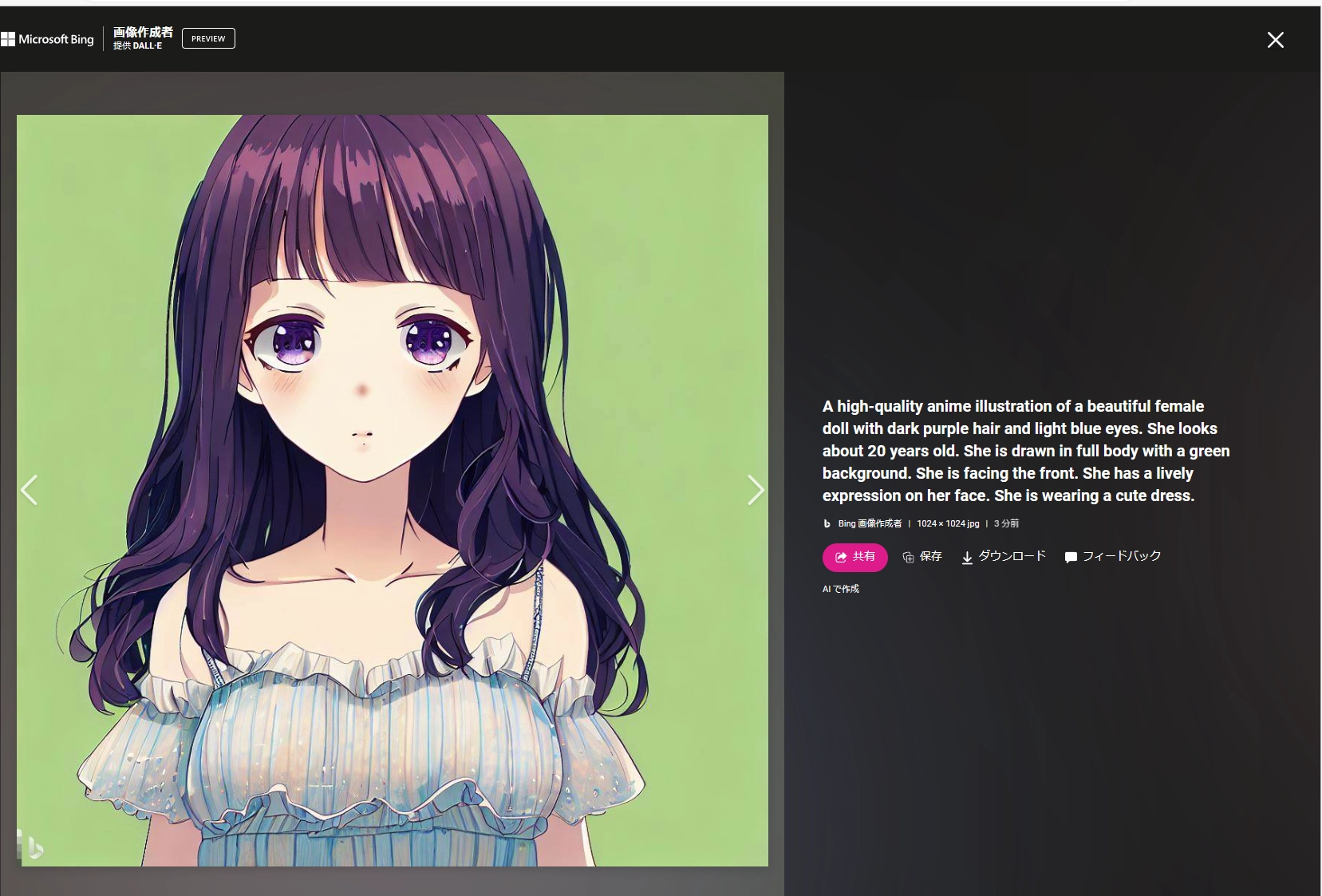
A high-quality anime illustration of a beautiful female doll with dark purple hair and light blue eyes. She looks about 20 years old. She is drawn in full body with a green background. She is facing the front. She has a lively expression on her face. She is wearing a cute dress.
このプロンプトを調整する形でいきましょうか。
ローカルPCでの画像生成
WebUIを起動して先程書いてもらったプロンプトで生成してみます。 全てデフォルトで出力するとこうなります。

いいですね。Pixivのマイナーキャラクターや子供アニメイラストを出してもらったような画像が出てきます。
ちなみに、この画像を生成するのに2秒程度です。 モデル変えて試していきましょう。
(exceptional, best aesthetic, new, newest, best quality, masterpiece, extremely detailed, anime, waifu:1.2)
A high-quality anime illustration of a beautiful female doll with dark purple hair and light blue eyes. She looks about 20 years old. She is drawn in full body with a green background. She is facing the front. She has a lively expression on her face. She is wearing a cute dress.
Negative Proptに追加してみます。
lowres, ((bad anatomy)), ((bad hands)), missing finger, extra digits, fewer digits, blurry, ((mutated hands and fingers)), (poorly drawn face), ((mutation)), ((deformed face)), (ugly), ((bad proportions)), ((extra limbs)), extra face, (double head), (extra head), ((extra feet)), monster, logo, cropped, worst quality, jpeg, humpbacked, long body, long neck, ((jpeg artifacts)), deleted, old, oldest, ((censored)), ((bad aesthetic)), (mosaic censoring, bar censor, blur censor)
上手く動かないよ
実行してみるとこのようなエラーに遭遇しました。
modules.devices.NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check
とりあえず言われた通りここにチェックを入れてみます。
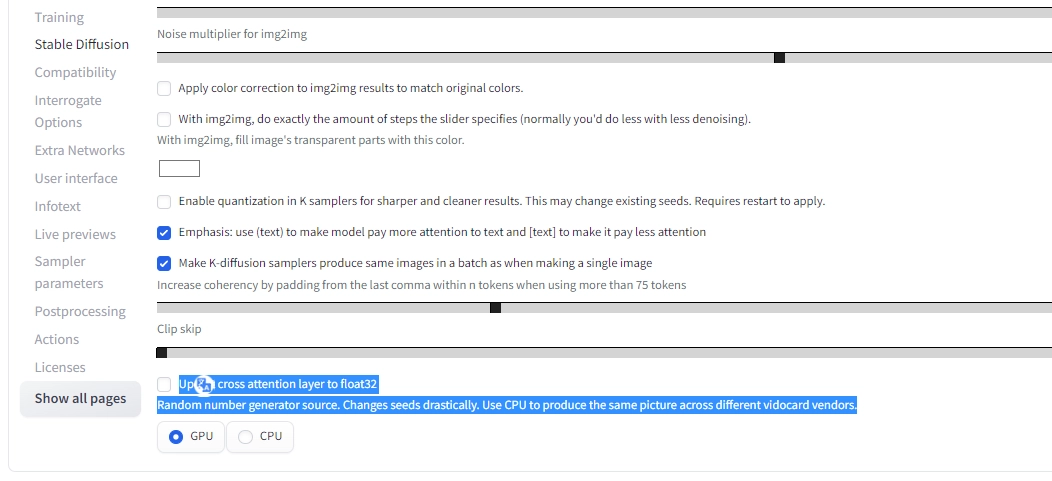
上の方に設定適用ボタンがあるので押しましょう。
再度生成してみる。
プロンプトは変えずに生成する。
いい感じに出てきた!!!
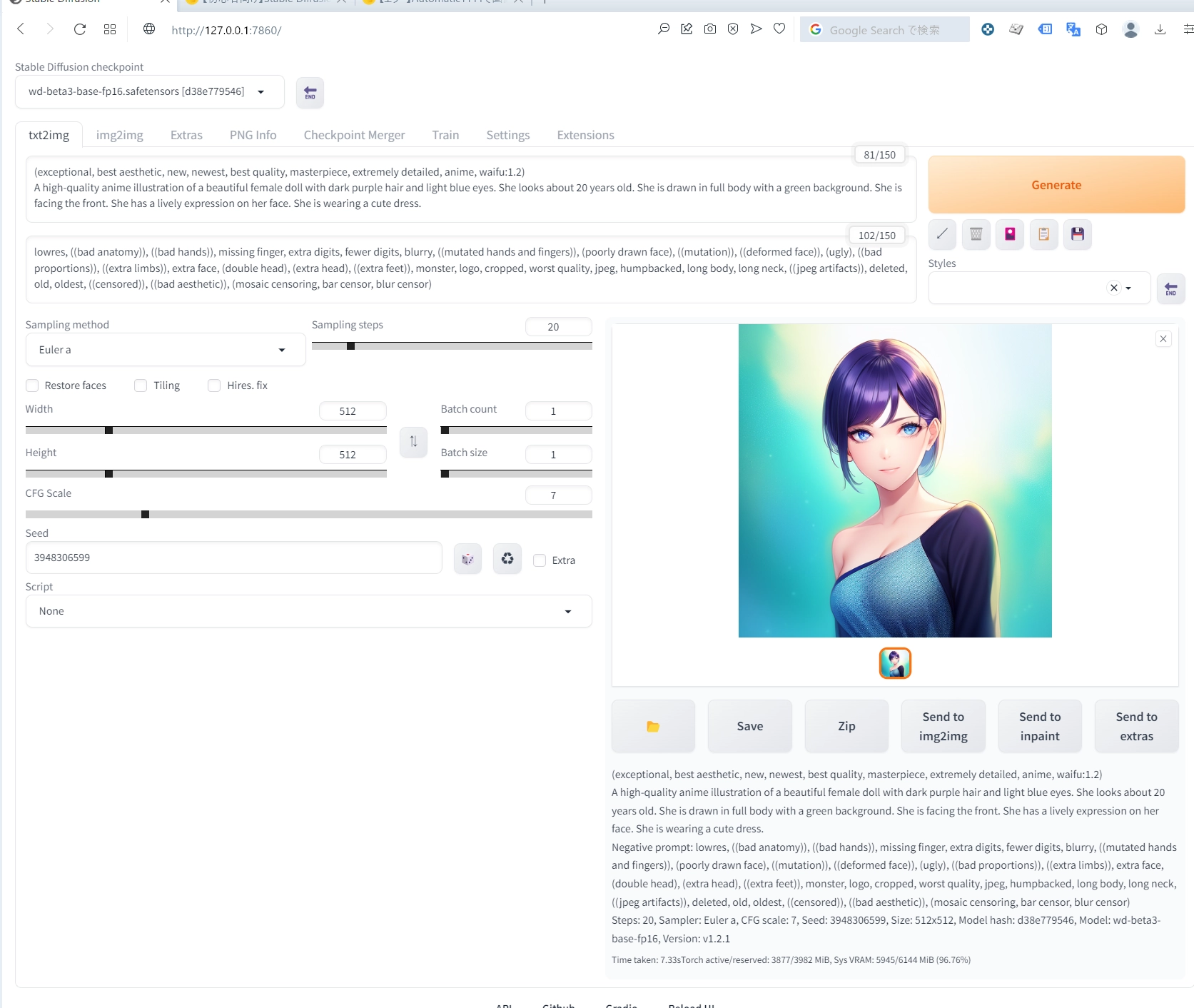
このモデルでも生成するのに6秒ぐらいでできますね。 こんな速度でこのクオリティのものが量産できるならたしかに食いっぱぐれるって危機感生まれるのもわかる気がします…。
このブログ記事で画像に困ることがあれば使っていこうかなと思うぐらいには便利で手軽ですね。
ということでこんな感じの画像が手に入りました。

まとめ
画像生成が思いの外簡単にできました。 今後は、壁打ちするように画像生成して好みのものが出たらデスクトップマスコット用に切り抜き、動かせるようにイジっていきましょう。 Live2Dがベターですかね。調べながら実装していきましょう。