EDINETから取得したXBRLファイルに含まれるテーブルデータを整形して表示してみる
はじめに
令和のブラックマンデーや植田ショックなど色々言われているような大きな下げにやられています。 最大200万円をえぐられる下げに流石に吐きそうになりながら日々を過ごし、投資戦略の見直しを余儀なくされました。
今回は、幸いにもすぐの戻してくれたので心に安寧がもたらされているのですが第二波、第三波が来ないとも限りません。 第二波とまではいかないですがジワジワと下げ始めています。
そうしたときに、有力な株を機械的にそして素早く見つける仕組み構築し、バリュー株の検索ができるようにしたいところです。
バフェット・コードや株プロはもちろん素晴らしく活用しているのですが、めぼしい株を目視で探すことが必要となりあまり多くの株を探すのも難しいです。 四季報とかも同様ですね。見るんですがやはり機械的なスクリーニングという面だと限界があります。
システム開発となると、それなりに時間はかかるのですが自前で用意して活用できたらいいなと思った次第です。
完成するのか、満足行く出来になるのかは未知数ですが、やってみないことには始まらないわけです。
大量のデータから、企業の業務内容や増益となっている理由を形態素解析して昨今のトレンドを探したり、大株主たちに人気の株はなにかと探してみたり、 各社の理論株価を求めて、一覧にして現在の株価と乖離が大きい会社をスクリーニングしたり やってみたいことはたくさんあります。
というわけで開発していきます。
本記事の範囲
- EDINETの値をすべて取得する
- DIVタグで取得される各種Tableを整形して表示する。
Future
- 時間情報とともにDBなどに格納して検索、分析できるようにする
- Pタグで含まれるテキストの整形
本記事の青果物
作りかけのコードはここに置いていくので皆さん、機能追加やコード修正など、どんな些細なものでも良いのでプルリクください。
いつ完成するのかも分からないですが、公開してWebサービスとして使えるようにしたいなと思っています。自分のためにも。
いくつかありますが、過去の記事も参考になるのでリンクを貼っておきます。
edinet解析用のクラスをelementlistから生成する
手法
過去の記事で、EDINET APIを叩いて有価証券報告書をDLするところ。 有価証券報告書に書かれた内容を取得するサポートクラスをExcelから生成しました。
今回のは、サポートクラスを用いてクボタの有価証券報告書に記載されている値をすべて取得を行います。
クラスに含まれる関数の取得にはinspectを利用すればよいのでそちらを活用します。 getmembersでメンバの情報が取得できるようになります。
このように書きました。
from jpcrp030200 import jpcrp030200
def main():
kubota = jpcrp030200(xbrl_file)
members = inspect.getmembers(kubota, predicate=inspect.ismethod)
メンバを取得したら、関数の名前と、実際に実行する部分を書いていきます。
nameには関数名。funcは関数を実行するためのオブジェクトが入ってます。 func()としたら、実行して返り値をresultに格納します。
for name, func in members:
if func.__code__.co_argcount == 1:
result = func() # 必要な引数があれば()内に指定
Tableを含む値の解析について
HTMLでそのまま出力するなら便利なんでしょうけど、Tableタグがテキストデータで直打ち記載された値が取得できます。 Beautifulsoup4で整形してPandasのDfに格納して表示しています。
厄介なのがテーブルはセル結合や値が含まれていないなどの影響で普通に崩れます。 なので1行ずつ読み取って整形するようにしました。
Tableでない値と処理を分けました。
soup = BeautifulSoup(result, 'lxml')
# 特定のテーブルを取得(例: 一つ目のテーブルを取得)
table = soup.find('table')
# テーブルが取得できているか確認
if table is None:
print(name,result)
else:
rows = []
for row in table.find_all('tr'):
# 各セルのテキストを取得
cells = [cell.get_text(strip=True) for cell in row.find_all(['td', 'th'])]
# セル数をヘッダー行のセル数に合わせる
if len(cells) < len(rows[0] if rows else cells):
cells.extend([''] * (len(rows[0]) - len(cells)))
rows.append(cells)
# データフレームを作成
try:
df = pd.DataFrame(rows[1:], columns=rows[0]) # 最初の行をヘッダーとして使用
except ValueError as e:
print(f"Error creating DataFrame: {e}")
# 列数が一致しない場合の対応処理
max_cols = max(len(row) for row in rows)
for row in rows:
row.extend([''] * (max_cols - len(row))) # 不足している列を補う
df = pd.DataFrame(rows[1:], columns=rows[0][:max_cols]) # ヘッダーも補正
print("Adjusted DataFrame:")
print(df)
コード全体
前回作成したクラスなどの実装は長いので割愛します。
このように書きました。また開発を進めていくうえで適宜関数などに分けて整理していきます。
import os
import zipfile
from arelle import ModelManager
from arelle import Cntlr
import pandas as pd
from pathlib import Path
import glob
import inspect
from bs4 import BeautifulSoup
import pandas as pd
from io import StringIO
from jpcrp030200 import jpcrp030200
def makeEdinetCompInfoList(edinetcodedlinfo_filepath):
edinet_info = pd.read_csv(edinetcodedlinfo_filepath, skiprows=1,
encoding='cp932')
edinet_info = edinet_info[["EDINETコード", "提出者業種"]]
edinet_info_list = edinet_info.values.tolist()
return edinet_info_list
def main():
# ZIPファイルのパス
zip_file_path = 'S100FFK6_有価証券報告書_株式会社 クボタ.zip'
# 一時フォルダを作成
temp_dir = 'temp'
os.makedirs(temp_dir, exist_ok=True)
# ZIPファイルを一時フォルダに展開
with zipfile.ZipFile(zip_file_path, 'r') as zip_file:
zip_file.extractall(temp_dir)
xbrl_file = glob.glob(temp_dir+'/**/PublicDoc/*.xbrl')[0]
# print(files[0])
# xbrl_file = getXBRLFilePath(temp_dir)
kubota = jpcrp030200(xbrl_file)
edinetcodedlinfo_filepath = '.\\EdinetcodeDlInfo.csv'
edinet_info_list = makeEdinetCompInfoList(edinetcodedlinfo_filepath)
kubota.setInfo(edinet_info_list)
# print('会社名',kubota.getCompanyNameCoverPage())
# print('従業員数',kubota.getNumberOfEmployees())
# print('売上高',kubota.getNetSales())
# print('資本金',kubota.getCapitalStockSummaryOfBusinessResults())
# print('潜在株式調整後1株当たり当期純利益',kubota.getDilutedEarningsPerShareSummaryOfBusinessResults())
# print('自己資本比率',kubota.getEquityToAssetRatioSummaryOfBusinessResults())
members = inspect.getmembers(kubota, predicate=inspect.ismethod)
for name, func in members:
if func.__code__.co_argcount == 1:
result = func() # 必要な引数があれば()内に指定
soup = BeautifulSoup(result, 'lxml')
# 特定のテーブルを取得(例: 一つ目のテーブルを取得)
table = soup.find('table')
# テーブルが取得できているか確認
if table is None:
print(name,result)
else:
rows = []
for row in table.find_all('tr'):
# 各セルのテキストを取得
cells = [cell.get_text(strip=True) for cell in row.find_all(['td', 'th'])]
# セル数をヘッダー行のセル数に合わせる
if len(cells) < len(rows[0] if rows else cells):
cells.extend([''] * (len(rows[0]) - len(cells)))
rows.append(cells)
# データフレームを作成
try:
df = pd.DataFrame(rows[1:], columns=rows[0]) # 最初の行をヘッダーとして使用
except ValueError as e:
print(f"Error creating DataFrame: {e}")
# 列数が一致しない場合の対応処理
max_cols = max(len(row) for row in rows)
for row in rows:
row.extend([''] * (max_cols - len(row))) # 不足している列を補う
df = pd.DataFrame(rows[1:], columns=rows[0][:max_cols]) # ヘッダーも補正
print("Adjusted DataFrame:")
print(df)
if __name__ == "__main__":
main()
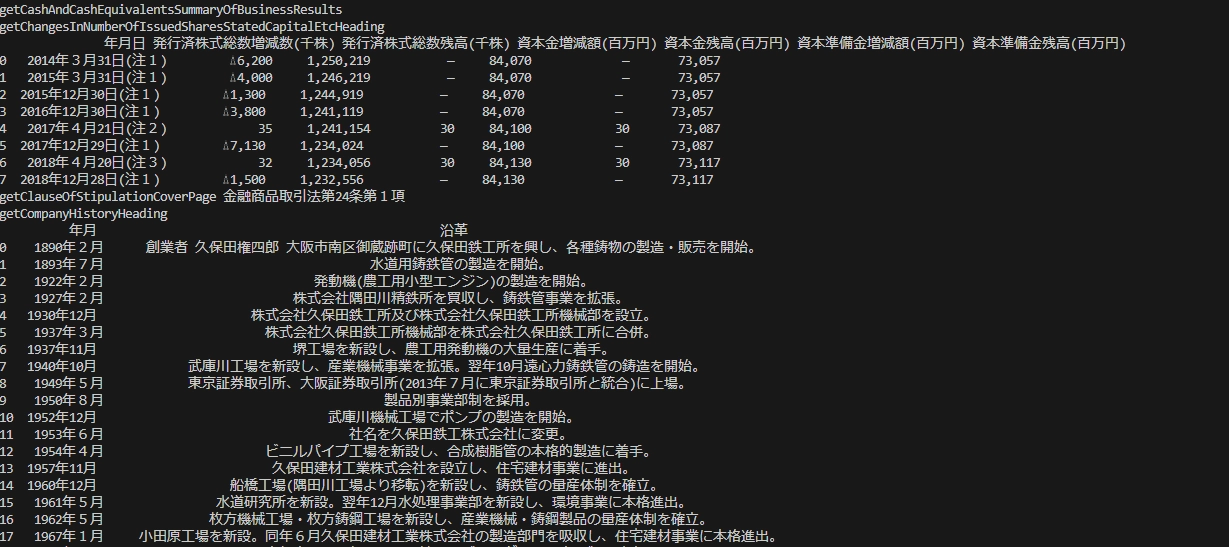
実行結果
実行するとこのような値が取得できます。

チラホラエラーになっていそうですね。

データの中身を精査していないのですが、どうも空白が多いように思います。 今後の課題として積んでおきましょう。
まとめ
いい感じに取得できました。 引き続き作っていきましょう。