有価証券報告書XBRLファイルに含まれるデータテーブルの整形及び出力を行いました
はじめに
株投資の方は本当にだめです。今月はひどいマイナスなので年間ベースの収支を見て心を落ち着かせているところです。 お金が沢山ある時はあまり創作意欲がわかないのですが、お金がなくなってくるとなにか対策を打とうという気持ちになります。
実際、貧すれば窮するという言葉にあるように、追い詰められた人間の判断が正常だとは考えにくいため、このタイミングで動き出すのは遅いわけですが…。 とはいえ何もしなければ奪われるだけなので、少しずつでも解析しやすいようにように整形していきましょう。
有価証券報告書には様々なデータが入っているのですが、ただ、HTMLライクな記載がベタ書きで書かれている部分も多く自前でパースする必要があります。 今回は、それを少しずつデータとして扱えるように整形していきます。しばらくこんなネタが続くかと思います。
本記事の範囲
- 事業の内容 [テキストブロック] の内容をベースにパースしていく。
手法
前回までに作成したサポートクラスを使います。
関数としてはこんな感じになっている部分です。
def getDescriptionOfBusinessTextBlock(self): #事業の内容 [テキストブロック]
return self.DescriptionOfBusinessTextBlock
取得する際にはこのように書けます。 前回までの記事と異なり、impoort部分が少し変わっています。 理由は見ての通りですが、jpcrpというフォルダに自動生成系のファイルを移動しているからです。
from jpcrp.jpcrp030200 import jpcrp030200
def main():
# ZIPファイルのパス
zip_file_path = 'S100FFK6_有価証券報告書_株式会社 クボタ.zip'
# 一時フォルダを作成
temp_dir = 'temp'
os.makedirs(temp_dir, exist_ok=True)
# ZIPファイルを一時フォルダに展開
with zipfile.ZipFile(zip_file_path, 'r') as zip_file:
zip_file.extractall(temp_dir)
xbrl_file = glob.glob(temp_dir+'/**/PublicDoc/*.xbrl')[0]
# print(files[0])
# xbrl_file = getXBRLFilePath(temp_dir)
kubota = jpcrp030200(xbrl_file)
html_content = kubota.getDescriptionOfBusinessTextBlock()
print('事業の内容',html_content)
出力するとこんな感じです。
事業の内容 <p style="page-break-before:always; line-height:0.75pt; width:100%; font-size:0.75pt;"> </p>
<h3 class="smt_head2">3 【事業の内容】</h3><p class="smt_text2" style="orphans:0;widows:0;padding-left:18pt;">当社グループは当社及び国内外185社の関係会社(連結子会社172社及び持分法適用会社13社)により構成され、機械、水・環境、その他の3事業セグメント区分にわたって多種多様な製品・サービスの提供を行っております。</p><p class="smt_text2" style="orphans:0;widows:0;padding-left:18pt;">当社(以下、原則として連結子会社を含む)の各事業セグメントにおける主要品目及び主な関係会社は以下のとおりです。<br/> また、当社はIFRSに準拠して連結財務諸表を作成しており、関係会社の範囲に含まれる連結子会社及び持分法適用会社はIFRSに基づいて決定しております。「第2 事業の状況」及び「第3 設備の状況」における関係会社の範囲についても同様です。</p><p class="smt_text3" style="orphans:0;widows:0;"> </p>
<h4 class="smt_head3">(1) 機械</h4><p class="smt_text3" style="orphans:0;widows:0;">主として農業機械及び農業関連商品、エンジン、建設機械の製造及び販売等を行っております。</p>
<h5 class="smt_head4">① 主要品目</h5>
<div class="tbld" style="text-align:center;margin-left:0.3pt;margin-right:0pt;margin-top:0pt;margin-bottom:0pt;">
<table cellspacing="0" cellpadding="0" style="border-collapse:collapse;border:solid 0pt #000000;width:435pt;table-layout:fixed;" class="align_center">
<colgroup>
<col style="width:75pt;min-width:75pt;"/>
<col style="width:360pt;min-width:360pt;"/>
</colgroup>
<tr style="height:36.0pt;min-height:36.0pt;">
<td valign="top" style="vertical-align:top;border-top-style:solid;border-top-width:0.75pt;border-bottom-style:solid;border-bottom-width:0.75pt;border-left-style:solid;border-left-width:0.75pt;border-right-style:solid;border-right-width:0.75pt;overflow:hidden;"><p class="smt_tblL" style="orphans:0;widows:0;padding-left:5.1pt;padding-right:0.0pt;margin-top:0.0pt;margin-bottom:0.0pt;letter-spacing:0.0pt;line-height:18.0pt;">農業機械及び<br/>農業関連商品</p>
</td>
<td valign="top" style="vertical-align:top;border-top-style:solid;border-top-width:0.75pt;border-bottom-style:solid;border-bottom-width:0.75pt;border-left-style:solid;border-left-width:0.75pt;border-right-style:solid;border-right-width:0.75pt;overflow:hidden;"><p class="smt_tblL" style="orphans:0;widows:0;padding-left:5.1pt;padding-right:0pt;margin-top:0pt;margin-bottom:0pt;letter-spacing:0.0pt;line-height:18.0pt;">トラクタ、耕うん機、コンバイン、田植機、芝刈機、<br/>ユーティリティビークル、その他農業機械、<br/>インプルメント、アタッチメント、ポストハーベスト機器、<br/>野菜機械、中間管理機、その他関連機器、<br/>ミニライスセンター、育苗・精米・園芸施設、</p><p class="smt_tblL" style="orphans:0;widows:0;text-align:justify;padding-left:5.1pt;padding-right:0pt;margin-top:0pt;margin-bottom:0pt;text-justify:inter-ideograph;text-indent:0pt;font-family:'MS 明朝';letter-spacing:0pt;line-height:18pt;font-size:9pt;">各種計量・計測・制御機器及びシステム、空調機器、空気清浄機</p>
</td>
流石にDBに格納するにしても情報過多ですし、最終的に何百とある会社データを数年分格納すると考えると容量が大きすぎるので削減していきましょう。
パーススクリプト
Beautifulsoupを使います。 事業内容はh3タグで書かれているようなので、下記のようにしました。
html_content = kubota.getDescriptionOfBusinessTextBlock()
# print('事業の内容',html_content)
# BeautifulSoupでHTMLを解析
soup = BeautifulSoup(html_content, 'html.parser')
# 事業の内容(h3タグとその後のpタグ)を探して収集
business_description = soup.find_all(['h3', 'p'], class_=['smt_head2', 'smt_text2'])
description_text = []
for desc in business_description:
# テキスト内容を取得してリストに追加
description_text.append(desc.get_text(strip=True))
# 事業内容の説明部分を出力
print("Business Description:")
for text in description_text:
print(text)
print("\n" + "-" * 40 + "\n")
実行するとこのような結果が得られます。いいですね。
Business Description:
3 【事業の内容】
当社グループは当社及び国内外185社の関係会社(連結子会社172社及び持分法適用会社13社)により構成され、機械、水・環境、その他の3事業セグメント区分にわたって多種多様な製品・サービスの提供を行っております。
当社(以下、原則として連結子会社を含む)の各事業セグメントにおける主要品目及び主な関係会社は以下のとおりです。また、当社はIFRSに準拠して連結財務諸表を作成しており、関係会社の範囲に含まれる連結子会社及び持分法適用会社はIFRSに基づいて決定しております。「第2 事業の状況」及び「第3 設備の状況」における関係会社の範囲についても同様です。
----------------------------------------
続いて、含まれる各種テーブルの抜き出しを行います。 やり方はほとんど同じなので説明も何もないのですがこんな感じです。
tableをすべて取得して、テーブルを出力します。テーブルの前にカテゴリやセグメントが書かれているのでそうした情報をタイトル情報として取得して出力します。
# テーブルを探しながら、前のタイトル情報を取得
tables = soup.find_all('table')
titles = []
# pandasを使ってHTMLのテーブルを読み込む
# tables = pd.read_html(html_content)
# タイトル情報を収集
for table in tables:
title_h4 = table.find_previous('h4', class_='smt_head3')
title_h5 = table.find_previous('h5', class_='smt_head4')
title_h6 = table.find_previous('h6', class_='smt_head5')
title = (title_h4.get_text(strip=True) if title_h4 else "") + "\n"+(title_h5.get_text(strip=True) if title_h5 else "") + " " + (title_h6.get_text(strip=True) if title_h6 else "")
titles.append(title)
# pandasでテーブルをDataFrameとして読み込む
dfs = pd.read_html(html_content)
# 各テーブルとタイトルを出力
for idx, (title, df) in enumerate(zip(titles, dfs)):
print(f"Table {idx + 1}: {title}")
print(df)
print("\n" + "-" * 40 + "\n")
Table 1: (1) 機械
① 主要品目
0 1
0 農業機械及び 農業関連商品 トラクタ、耕うん機、コンバイン、田植機、芝刈機、 ユーティリティビークル、その他農業機械、 ...
1 エンジン 農業機械用・建設機械用・産業機械用・発電機用等各種エンジン
2 建設機械 ミニバックホー、ホイールローダ、コンパクトトラックローダ、 スキッドステアローダ、その他各種...
----------------------------------------
Table 2: (1) 機械
② 主な関係会社 (製造・販売)
0 1
0 [国内] クボタ空調㈱
1 [海外] クボタマニュファクチュアリング オブ アメリカ Corp.、 クボタインダストリアル イクイ...
----------------------------------------
Table 3: (1) 機械
② 主な関係会社 (販売・サービス等)
0 1
0 [国内] ㈱北海道クボタ他農業機械販売会社12社、㈱クボタ建機ジャパン
1 [海外] クボタノースアメリカ Corp.、クボタトラクター Corp.、 クボタエンジンアメリカ C...
----------------------------------------
(以下略)
このように撮ることができます。
テーブルカテゴリの集約
クボタさんだとこのようなテーブル構造になっているだけの可能性もありますが、 主要な関係会社などはセグメントごとに分かれて出力しており企業規模が大きくなればなるほどテーブルが増加することが予想されます。ある程度固まっていたほうが処理はし易いかと思うのでカテゴリ集約を行いたいです。
だんだん長くなってくるのですが、下記のように書いてみました。
html_content = kubota.getDescriptionOfBusinessTextBlock()
# print('事業の内容',html_content)
# BeautifulSoupでHTMLを解析
soup = BeautifulSoup(html_content, 'html.parser')
# 事業の内容(h3タグとその後のpタグ)を探して収集
business_description = soup.find_all(['h3', 'p'], class_=['smt_head2', 'smt_text2'])
description_text = []
for desc in business_description:
# テキスト内容を取得してリストに追加
description_text.append(desc.get_text(strip=True))
# 事業内容の説明部分を出力
print("Business Description:")
for text in description_text:
print(text)
print("\n" + "-" * 40 + "\n")
# テーブルを探しながら、前のタイトル情報を取得
tables = soup.find_all('table')
# タイトル情報を収集してテーブルごとにカテゴリ分け
table_groups = {}
for table in tables:
title_h4 = table.find_previous('h4', class_='smt_head3')
title_h5 = table.find_previous('h5', class_='smt_head4')
title_h6 = table.find_previous('h6', class_='smt_head5')
# `title_h5` をキーにして同じカテゴリを集約
main_title = title_h5.get_text(strip=True) if title_h5 else "No Title H5"
sub_title = title_h6.get_text(strip=True) if title_h6 else ""
# テーブルをpandas DataFrameとして読み込む
df = pd.read_html(str(table))[0]
df['Category'] = sub_title # サブタイトルを新しい列として追加
# 同じタイトルのテーブルを集約
if main_title in table_groups:
table_groups[main_title].append(df)
else:
table_groups[main_title] = [df]
# 事業内容の説明部分を出力
print("Business Description:")
for text in description_text:
print(text)
print("\n" + "-" * 40 + "\n")
# 集約されたテーブルを出力
for idx, (main_title, dfs) in enumerate(table_groups.items()):
combined_df = pd.concat(dfs, ignore_index=True)
print(f"Table {idx + 1}: {main_title}")
print(combined_df)
print("\n" + "-" * 40 + "\n")
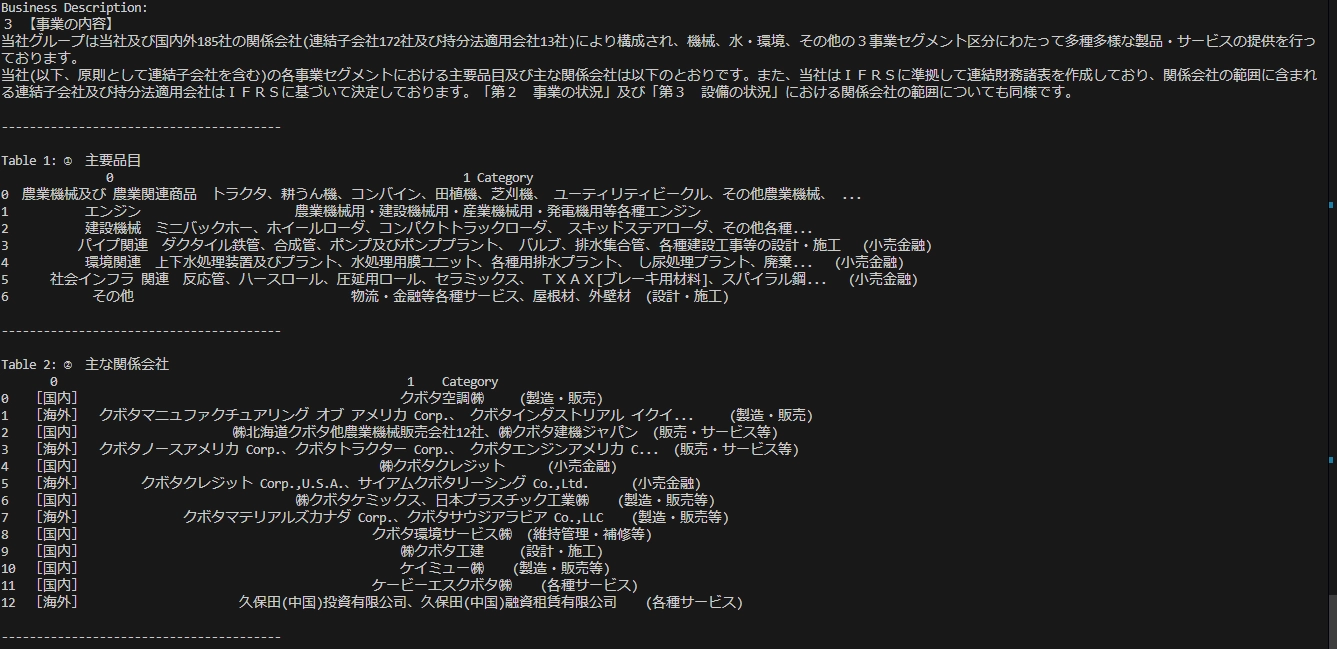
実行するとこのような感じです。 なかなかキレイに出ているように思います。
Business Description:
3 【事業の内容】
当社グループは当社及び国内外185社の関係会社(連結子会社172社及び持分法適用会社13社)により構成され、機械、水・環境、その他の3事業セグメント区分にわたって多種多様な製品・サービスの提供を行っ ております。
当社(以下、原則として連結子会社を含む)の各事業セグメントにおける主要品目及び主な関係会社は以下のとおりです。また、当社はIFRSに準拠して連結財務諸表を作成しており、関係会社の範囲に含まれ る連結子会社及び持分法適用会社はIFRSに基づいて決定しております。「第2 事業の状況」及び「第3 設備の状況」における関係会社の範囲についても同様です。
----------------------------------------
Table 1: ① 主要品目
0 1 Category
0 農業機械及び 農業関連商品 トラクタ、耕うん機、コンバイン、田植機、芝刈機、 ユーティリティビークル、その他農業機械、 ...
1 エンジン 農業機械用・建設機械用・産業機械用・発電機用等各種エンジン
2 建設機械 ミニバックホー、ホイールローダ、コンパクトトラックローダ、 スキッドステアローダ、その他各種...
3 パイプ関連 ダクタイル鉄管、合成管、ポンプ及びポンププラント、 バルブ、排水集合管、各種建設工事等の設計・施工 (小売金融)
4 環境関連 上下水処理装置及びプラント、水処理用膜ユニット、各種用排水プラント、 し尿処理プラント、廃棄... (小売金融)
5 社会インフラ 関連 反応管、ハースロール、圧延用ロール、セラミックス、 TXAX[ブレーキ用材料]、スパイラル鋼... (小売金融)
6 その他 物流・金融等各種サービス、屋根材、外壁材 (設計・施工)
----------------------------------------
Table 2: ② 主な関係会社
0 1 Category
0 [国内] クボタ空調㈱ (製造・販売)
1 [海外] クボタマニュファクチュアリング オブ アメリカ Corp.、 クボタインダストリアル イクイ... (製造・販売)
2 [国内] ㈱北海道クボタ他農業機械販売会社12社、㈱クボタ建機ジャパン (販売・サービス等)
3 [海外] クボタノースアメリカ Corp.、クボタトラクター Corp.、 クボタエンジンアメリカ C... (販売・サービス等)
4 [国内] ㈱クボタクレジット (小売金融)
5 [海外] クボタクレジット Corp.,U.S.A.、サイアムクボタリーシング Co.,Ltd. (小売金融)
6 [国内] ㈱クボタケミックス、日本プラスチック工業㈱ (製造・販売等)
7 [海外] クボタマテリアルズカナダ Corp.、クボタサウジアラビア Co.,LLC (製造・販売等)
8 [国内] クボタ環境サービス㈱ (維持管理・補修等)
9 [国内] ㈱クボタ工建 (設計・施工)
10 [国内] ケイミュー㈱ (製造・販売等)
11 [国内] ケービーエスクボタ㈱ (各種サービス)
12 [海外] 久保田(中国)投資有限公司、久保田(中国)融資租賃有限公司 (各種サービス)
----------------------------------------
結果
関数化して他のテキストブロックにも適用してみました。XBRLではある程度統一的な記法になっているようなのでそのまま使いまわせそうですね。 DBに詰め込む際には再度修正が必要そうですが見やすくなってきましたね。
沿革に適用した様子。
Business Description:
2 【沿革】
----------------------------------------
Table 1: No Title H5
0 1 Category
0 年月 沿革
1 1890年2月 創業者 久保田権四郎 大阪市南区御蔵跡町に久保田鉄工所を興し、各種鋳物の製造・販売を開始。
2 1893年7月 水道用鋳鉄管の製造を開始。
3 1922年2月 発動機(農工用小型エンジン)の製造を開始。
4 1927年2月 株式会社隅田川精鉄所を買収し、鋳鉄管事業を拡張。
5 1930年12月 株式会社久保田鉄工所及び株式会社久保田鉄工所機械部を設立。
6 1937年3月 株式会社久保田鉄工所機械部を株式会社久保田鉄工所に合併。
7 1937年11月 堺工場を新設し、農工用発動機の大量生産に着手。
8 1940年10月 武庫川工場を新設し、産業機械事業を拡張。翌年10月遠心力鋳鉄管の鋳造を開始。
9 1949年5月 東京証券取引所、大阪証券取引所(2013年7月に東京証券取引所と統合)に上場。
10 1950年8月 製品別事業部制を採用。
11 1952年12月 武庫川機械工場でポンプの製造を開始。
12 1953年6月 社名を久保田鉄工株式会社に変更。
13 1954年4月 ビニルパイプ工場を新設し、合成樹脂管の本格的製造に着手。
14 1957年11月 久保田建材工業株式会社を設立し、住宅建材事業に進出。
15 1960年12月 船橋工場(隅田川工場より移転)を新設し、鋳鉄管の量産体制を確立。
16 1961年5月 水道研究所を新設。翌年12月水処理事業部を新設し、環境事業に本格進出。
17 1962年5月 枚方機械工場・枚方鋳鋼工場を新設し、産業機械・鋳鋼製品の量産体制を確立。
18 1967年1月 小田原工場を新設。同年6月久保田建材工業株式会社の製造部門を吸収し、住宅建材事業に本格進出。
19 1969年5月 宇都宮工場を新設し、田植機、バインダーの量産体制を確立。
20 1972年6月 関東大径鋼管株式会社を吸収合併。市川工場と改称し、引続きスパイラル鋼管を製造。
21 1972年9月 米国にクボタトラクター Corp.を設立し、北米におけるトラクタの販売体制を強化。
22 1973年9月 久宝寺工場を新設。船出町工場より製造設備を移設し、電装機器製造工場とする。
23 1974年3月 フランスにヨーロッパクボタトラクタ販売有限会社(現 クボタヨーロッパ S.A.S.)を設立し...
24 1975年8月 農業用トラクタの専門量産工場として筑波工場を新設。
25 1976年11月 ニューヨーク証券取引所に上場。(2013年7月に同取引所上場廃止。)
26 1980年4月 外壁材専門工場として鹿島工場を新設。
27 1985年1月 エンジン専門工場として堺製造所に堺臨海工場を新設。
28 1990年4月 社名を株式会社クボタに変更。
29 2002年10月 関西地区における環境エンジニアリング事業の拠点として阪神事務所を新設。
30 2003年12月 住宅建材事業を会社分割により、クボタ松下電工外装株式会社(現 ケイミュー株式会社)に承継。
31 2004年8月 タイの関連会社ザ・サイアムクボタインダストリー Co.,Ltd.(現 サイアムクボタコーポレ...
32 2005年4月 シーアイ化成株式会社との合成樹脂管事業統合により、クボタシーアイ株式会社(現 株式会社クボタ...
33 2007年9月 タイにおけるトラクタの生産拠点としてサイアムクボタトラクター Co.,Ltd.(現 サイアム...
34 2009年12月 サウジアラビアにおける鋳鋼事業の拠点としてクボタサウジアラビア Co.,LLCを設立。
35 2012年3月 畑作用インプルメントメーカーであるノルウェーのクバンランド ASA(現 クバンランド AS)...
36 2013年12月 フランスに畑作用大型トラクタの生産拠点としてクボタファームマシナリーヨーロッパS.A.S.を設立。
37 2016年7月 インプルメントメーカーである米国のグレートプレーンズマニュファクチュアリング,Inc.を買収...
----------------------------------------
株式の総数に適用した様子
----------------------------------------
Table 1: ① 【株式の総数】
0 1 Category
0 種類 発行可能株式総数(株)
1 普通株式 1874700000
2 計 1874700000
----------------------------------------
まとめ
まだまだやること多そうでげんなりするのですが、少しずつ作っていきましょう。